PowerInfer源码解析(二):计算图构建与算子调用
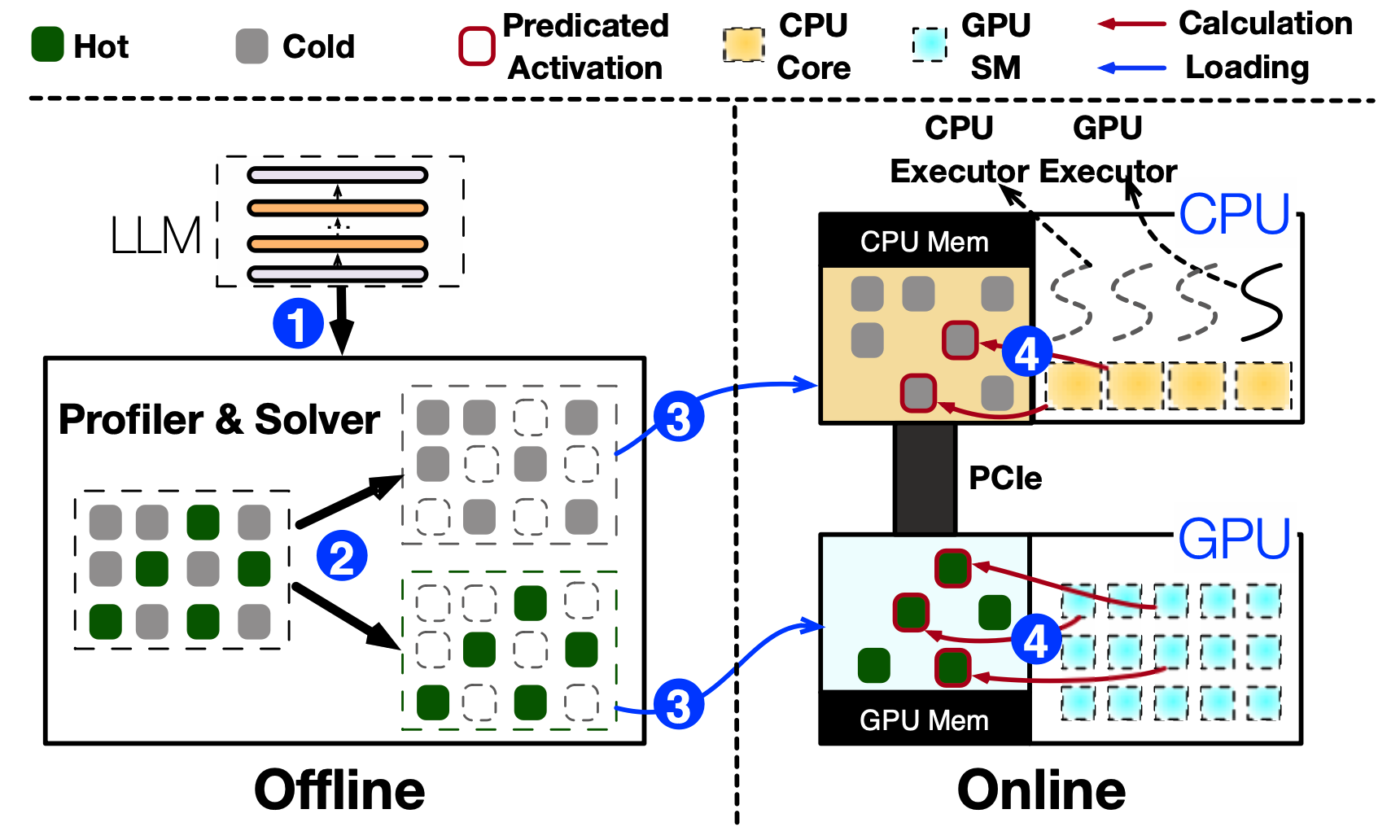
上篇文章概括了PowerInfer的模型加载过程,这次我们来看一看推理时的流程。
相关
计算图构建
让我们回到examples/main/main.cpp:main,模型在加载之后,又经过了一堆推理时的参数准备,最终调用llama_decode进行推理。
int main(int argc, char ** argv) {
// -- snip --
for (int i = 0; i < (int) embd.size(); i += params.n_batch) {
int n_eval = (int) embd.size() - i;
if (n_eval > params.n_batch) {
n_eval = params.n_batch;
}
LOG("eval: %s\n", LOG_TOKENS_TOSTR_PRETTY(ctx, embd).c_str());
if (llama_decode(ctx, llama_batch_get_one(&embd[i], n_eval, n_past, 0))) {
LOG_TEE("%s : failed to eval\n", __func__);
return 1;
}
n_past += n_eval;
LOG("n_past = %d\n", n_past);
}
// -- snip --
}
llama_decode会调用到llama_decode_internal,llama_decode_internal则会使用llama_build_graph来构建计算图。
对于LLM_ARCH_LLAMA和LLM_ARCH_BAMBOO模型架构,PowerInfer调用llm.build_llama_variants来生成计算图(替代了原有的llm.build_llama函数)。
对原先的build_llama而言,新的build_llama_variants的区别主要在于,对于使用sparse inference的情况,PowerInfer会使用单独的llm_build_ffn_sparse(区别于llm_build_ffn)来生成FFN部分。
struct ggml_cgraph * build_llama_variants() {
// -- snip --
if (llama_use_sparse_inference(&model)) {
llm_build_cb_short cbs = [&](ggml_tensor * cur, const char * name) {
std::string name_str = std::string(name) + "-" + std::to_string(il);
ggml_set_name(cur, name_str.c_str());
};
// We only offload the ffn input to GPU if all neurons are offloaded
if (model.layers[il].gpu_offload_ratio >= 1.) {
cb(cur, "ffn_norm", il);
} else {
cbs(cur, "ffn_norm");
}
cur = llm_build_ffn_sparse(ctx0, cur,
model.layers[il].ffn_up, NULL,
model.layers[il].ffn_gate, NULL,
model.layers[il].ffn_down_t, NULL,
model.layers[il].mlp_pre_w1,
model.layers[il].mlp_pre_w2,
ffn_inp, // as for now, llama's pred use the same input as the ffn
model.layers[il].gpu_idx,
model.layers[il].gpu_bucket, model.layers[il].ffn_gate_gpu, model.layers[il].ffn_down_gpu, model.layers[il].ffn_up_gpu,
LLM_FFN_RELU, gate_type, model.layers[il].gpu_offload_ratio, cbs);
} else {
// fallback to dense
cb(cur, "ffn_norm", il);
llm_ffn_op_type act_type = model.arch == LLM_ARCH_BAMBOO ? LLM_FFN_RELU : LLM_FFN_SILU;
cur = llm_build_ffn(ctx0, cur,
model.layers[il].ffn_up, NULL,
model.layers[il].ffn_gate, NULL,
model.layers[il].ffn_down, NULL,
act_type, gate_type, cb, il);
}
// -- snip --
}
在llm_build_ffn_sparse中我们可以具体看见FFN部分是如何被构建的。我们可以先看一下原版Llama的MLP的具体架构。
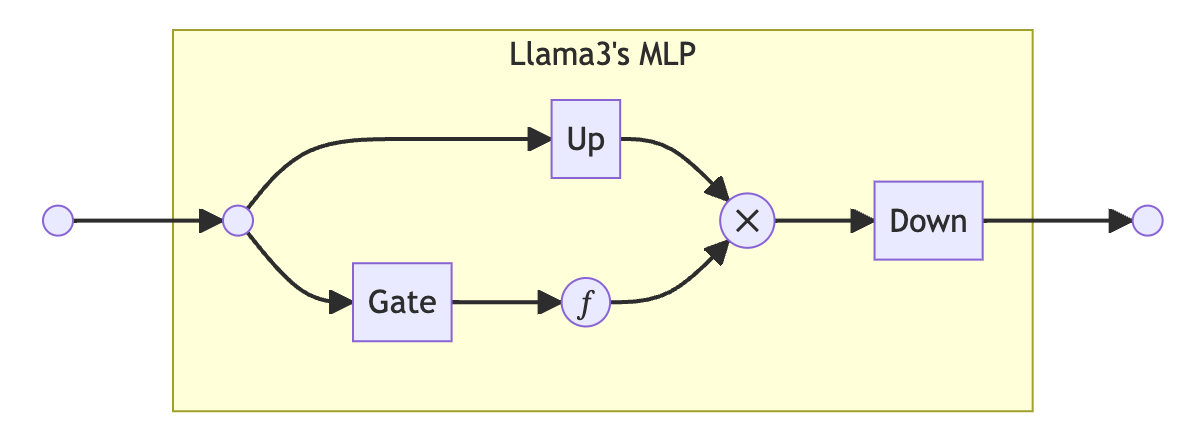
图中的Gate,Up和Down均为线性层。即Llama的MLP的输入会一边经过Gate然后激活函数,另一边经过Up,最后两者乘起来再经过Down,最终得到MLP的输出。
至于PowerInfer,则在前面加了一个Predictor用来预测当前层的哪些neurons会被激活。并且,这些neurons可能是分别分布在GPU和CPU上的,同时还要考虑利用到激活的稀疏性,因此还会调用特制的算子来进行计算。
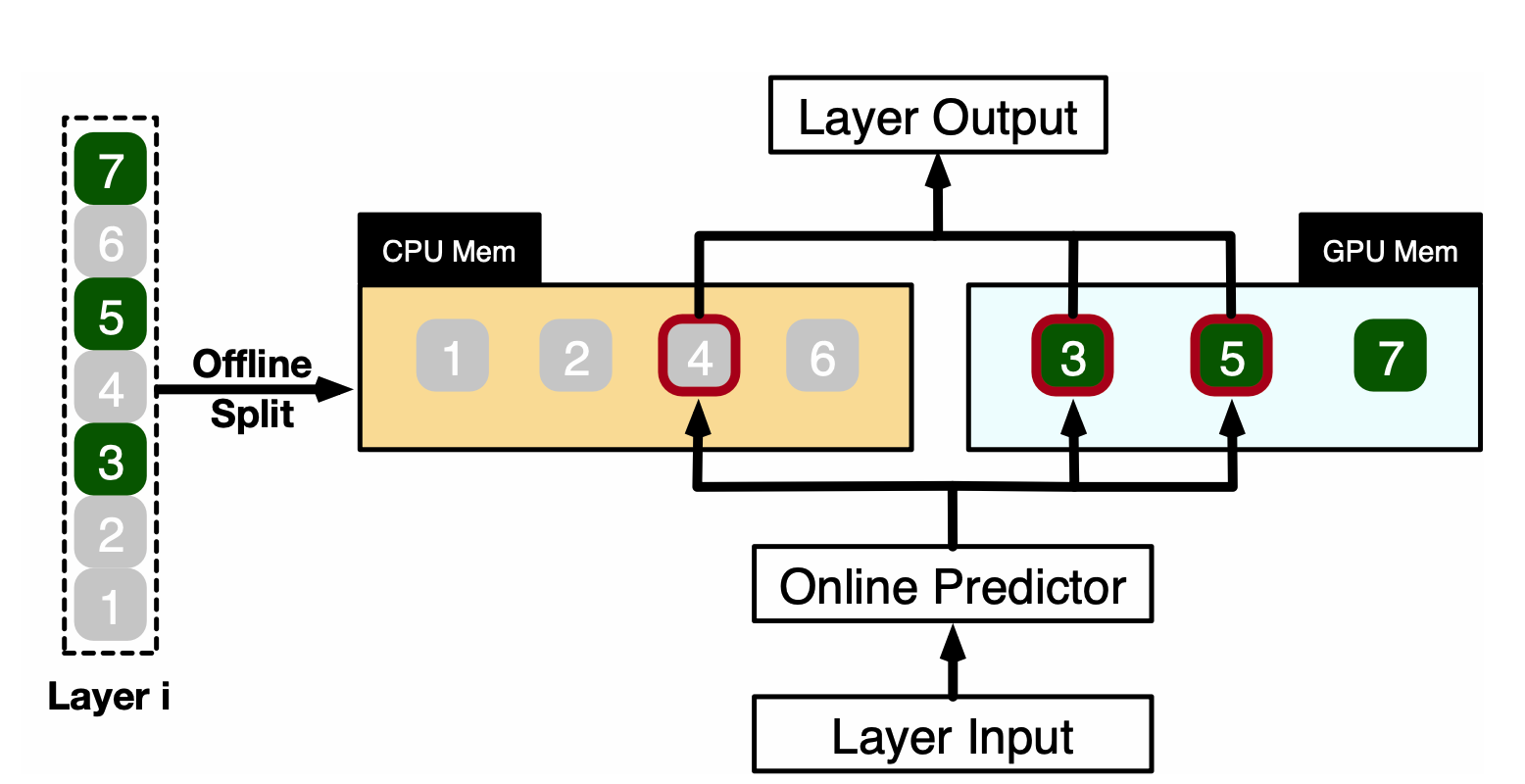
于是来看看代码。
static struct ggml_tensor * llm_build_ffn_sparse(
struct ggml_context * ctx,
struct ggml_tensor * cur,
struct ggml_tensor * up,
struct ggml_tensor * up_b,
struct ggml_tensor * gate,
struct ggml_tensor * gate_b,
struct ggml_tensor * down_t,
struct ggml_tensor * down_b,
struct ggml_tensor * pre_w1,
struct ggml_tensor * pre_w2,
struct ggml_tensor * pred_inpl,
struct ggml_tensor * gpu_index,
struct ggml_tensor * gpu_bucket,
struct ggml_tensor * gate_gpu,
struct ggml_tensor * down_gpu,
struct ggml_tensor * up_gpu,
llm_ffn_op_type type_op,
llm_ffn_gate_type type_gate,
double gpu_offload_ratio,
const llm_build_cb_short & cb_outer) {
bool full_gpu = gpu_offload_ratio >= 1.0;
ggml_tensor * ffn_input = cur;
llm_build_cb_short cb = [&cb_outer](struct ggml_tensor * tensor, const char * name) {
cb_outer(tensor, name);
#if defined(GGML_USE_CUBLAS)
// Determine offloading based on src[0] (weight for both mul and axpy)
bool operates_on_gpu = tensor->src[0]->backend == GGML_BACKEND_GPU;
if (operates_on_gpu) {
ggml_cuda_assign_buffers_no_alloc(tensor);
}
#endif
};
// prepare sparse idx
ggml_tensor * idx = ggml_mul_mat(ctx, pre_w1, pred_inpl);
cb(idx, "mlp_pre_hidden");
idx = ggml_relu(ctx, idx);
cb(idx, "mlp_pre_relu");
idx = ggml_mul_mat(ctx, pre_w2, idx);
// If the FFN layer is not fully offloaded, we need to transfer the sparsity index
// back to the CPU to avoid synchronization issues.
(full_gpu ? cb : cb_outer)(idx, "mlp_pre_out");
auto act_fn = [&](ggml_tensor * tensor, const char * name) {
switch (type_op) {
case LLM_FFN_RELU:
{
tensor = ggml_relu(ctx, tensor);
cb(tensor, name);
} break;
default:
GGML_ASSERT(false && "unsupported activation function");
}
return tensor;
};
// FFN up
struct ggml_tensor * up_out = llm_build_sparse_mul_mat(ctx, up, ffn_input, idx, up_gpu, gpu_index, gpu_bucket, cb_outer, "up", full_gpu);
if (up_b) {
up_out = ggml_add(ctx, up_out, up_b);
cb(up_out, "ffn_up_b");
}
struct ggml_tensor * gate_out = nullptr;
if (gate) {
ggml_tensor * gate_input = (type_gate == LLM_FFN_PAR || type_gate == LLM_FFN_SYM) ? ffn_input : up_out;
gate_out = llm_build_sparse_mul_mat(ctx, gate, gate_input, idx, gate_gpu, gpu_index, gpu_bucket, cb_outer, "gate", full_gpu);
if (gate_b) {
gate_out = ggml_add(ctx, gate_out, gate_b);
cb(gate_out, "ffn_gate_b");
}
switch (type_gate) {
case LLM_FFN_PAR:
{
ggml_tensor * act_gate = act_fn(gate_out, "ffn_gate_act");
cur = ggml_mul(ctx, act_gate, up_out);
cb(cur, "ffn_gate_par");
} break;
case LLM_FFN_SYM:
{
ggml_tensor * act_gate = act_fn(gate_out, "ffn_gate_act");
ggml_tensor * act_up = act_fn(up_out, "ffn_up_act");
cur = ggml_mul(ctx, act_gate, act_up);
cb(cur, "ffn_gate_sym");
} break;
case LLM_FFN_SEQ:
{
cur = act_fn(gate_out, "ffn_gate_act");
} break;
default: GGML_ASSERT(false && "unsupported gate type");
}
} else {
cur = act_fn(up_out, "ffn_up_act");
}
cur = llm_build_sparse_axpy(ctx, down_t, cur, idx, down_gpu, gpu_index, gpu_bucket, cb_outer, "down", full_gpu);
if (down_b) {
cur = ggml_add(ctx, cur, down_b);
cb(cur, "ffn_down_b");
}
return cur;
}
让我们来具体看一下里面的内容。
首先是一个矩阵乘、一个ReLU、再一个矩阵乘,组成了predictor部分,张量名字分别为mlp_pre_hidden、mlp_pre_relu和mlp_pre_out,最终得到sparse idx,即哪些neurons会被激活的预测结果。
// prepare sparse idx
ggml_tensor * idx = ggml_mul_mat(ctx, pre_w1, pred_inpl);
cb(idx, "mlp_pre_hidden");
idx = ggml_relu(ctx, idx);
cb(idx, "mlp_pre_relu");
idx = ggml_mul_mat(ctx, pre_w2, idx);
// If the FFN layer is not fully offloaded, we need to transfer the sparsity index
// back to the CPU to avoid synchronization issues.
(full_gpu ? cb : cb_outer)(idx, "mlp_pre_out");
定义了后续所使用的激活函数,目前只支持ReLU。
auto act_fn = [&](ggml_tensor * tensor, const char * name) {
switch (type_op) {
case LLM_FFN_RELU:
{
tensor = ggml_relu(ctx, tensor);
cb(tensor, name);
} break;
default:
GGML_ASSERT(false && "unsupported activation function");
}
return tensor;
};
回忆Llama MLP的结构,首先一边是ffn_up。
// FFN up
struct ggml_tensor * up_out = llm_build_sparse_mul_mat(ctx, up, ffn_input, idx, up_gpu, gpu_index, gpu_bucket, cb_outer, "up", full_gpu);
if (up_b) {
up_out = ggml_add(ctx, up_out, up_b);
cb(up_out, "ffn_up_b");
}
另一边是ffn_gate以及后续的激活函数。
注意这里又有一个gate类型的选择。其类型分别有:
LLM_FFN_SEQ:ffn_gate和ffn_up的计算是顺序的,先计算ffn_up,再把ffn_up的结果作为ffn_gate的输入。LLM_FFN_PAR:ffn_gate与ffn_up的计算是并行的。ffn_gate的输入是ffn_input,等输入经过ffn_gate和激活函数后再和up_out相乘。LLM_FFN_SYM:与LLM_FFN_PAR的区别是,up_out也要先经过激活函数才与ffn_gate_act相乘。
最后,结果会再经过ffn_down,进行一个axpy操作,得到最终结果。
struct ggml_tensor * gate_out = nullptr;
if (gate) {
ggml_tensor * gate_input = (type_gate == LLM_FFN_PAR || type_gate == LLM_FFN_SYM) ? ffn_input : up_out;
gate_out = llm_build_sparse_mul_mat(ctx, gate, gate_input, idx, gate_gpu, gpu_index, gpu_bucket, cb_outer, "gate", full_gpu);
if (gate_b) {
gate_out = ggml_add(ctx, gate_out, gate_b);
cb(gate_out, "ffn_gate_b");
}
switch (type_gate) {
case LLM_FFN_PAR:
{
ggml_tensor * act_gate = act_fn(gate_out, "ffn_gate_act");
cur = ggml_mul(ctx, act_gate, up_out);
cb(cur, "ffn_gate_par");
} break;
case LLM_FFN_SYM:
{
ggml_tensor * act_gate = act_fn(gate_out, "ffn_gate_act");
ggml_tensor * act_up = act_fn(up_out, "ffn_up_act");
cur = ggml_mul(ctx, act_gate, act_up);
cb(cur, "ffn_gate_sym");
} break;
case LLM_FFN_SEQ:
{
cur = act_fn(gate_out, "ffn_gate_act");
} break;
default: GGML_ASSERT(false && "unsupported gate type");
}
} else {
cur = act_fn(up_out, "ffn_up_act");
}
需要注意的是,llm_build_ffn_sparse调用了专门的llm_build_sparse_mul_mat来进行矩阵乘,其以使用sparse idx来利用激活的稀疏性特征。
在llm_build_sparse_mul_mat中,如果是全部计算卸载到GPU的情况则直接对up_gpu和输入调用ggml_mul_mat_idx并返回即可。
否则,对CPU上的up和GPU上的up_gpu分别使用ggml_mul_mat_idx和ggml_mul_mat_idx_upscale进行计算,然后再把得到的结果out和out_gpu使用ggml_add进行汇总,得到最终结果。
static struct ggml_tensor * llm_build_sparse_mul_mat(
struct ggml_context * ctx,
struct ggml_tensor * up,
struct ggml_tensor * inp,
struct ggml_tensor * idx,
struct ggml_tensor * up_gpu,
struct ggml_tensor * gpu_index,
struct ggml_tensor * gpu_bucket,
const llm_build_cb_short & cb,
const char * name,
bool full_gpu) {
std::string full_name = "ffn_" + std::string(name) + "_sparse";
ggml_tensor * out = nullptr;
#ifdef GGML_USE_HIPBLAS
// WARNING: THIS IS A HACK!
// if up_gpu->data is null
// inference fails when model exceeds 40B on rocm device
// so we just let up_gpu->data point to itself
up_gpu->data = up_gpu;
#endif
#ifdef GGML_USE_CUBLAS
// Full offloading fast path
if (full_gpu) {
GGML_ASSERT(up_gpu && "full_gpu but no up_gpu");
out = ggml_mul_mat_idx(ctx, up_gpu, inp, idx, NULL);
ggml_cuda_assign_buffers_no_alloc(out);
cb(out, (full_name).c_str());
return out;
}
#endif
out = ggml_mul_mat_idx(ctx, up, inp, idx, gpu_index);
cb(out, full_name.c_str());
#ifdef GGML_USE_CUBLAS
if (up_gpu) {
ggml_tensor * out_gpu = ggml_mul_mat_idx_upscale(ctx, up_gpu, inp, idx, gpu_bucket, out->ne[0]);
ggml_cuda_assign_buffers_no_alloc(out_gpu);
cb(out_gpu, (full_name + "_gpu").c_str());
out = ggml_add(ctx, out, out_gpu);
// We don't need to assign buffers here, as the output will be passed into Axpy,
// which in this case, is also a hybrid operation.
cb(out, (full_name + "_merged").c_str());
}
#endif
return out;
}
查看所调用的ggml_mul_mat_idx。我们可以看见,a,b,sparse idx(由predictor得到)和gpu_idx(offline时候得到)分别被作为了四个src参与计算。op使用的是GGML_OP_MUL_MAT_SPARSE(区别于GGML_OP_MUL_MAT)。
struct ggml_tensor * ggml_mul_mat_idx(
struct ggml_context * ctx,
struct ggml_tensor * a,
struct ggml_tensor * b,
struct ggml_tensor * sparse_idx,
// Under hybrid inference, this tensor is to indicate which row are offloaded to GPU;
// When using full GPU inference, it is NULL.
struct ggml_tensor * gpu_idx) {
GGML_ASSERT(!ggml_is_transposed(a));
bool is_node = false;
if (a->grad || b->grad) {
is_node = true;
}
const int64_t ne[4] = { a->ne[1], b->ne[1], b->ne[2], b->ne[3] };
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, MAX(a->n_dims, b->n_dims), ne);
result->op = GGML_OP_MUL_MAT_SPARSE;
result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
result->src[0] = a;
result->src[1] = b;
result->src[2] = sparse_idx;
result->src[3] = gpu_idx;
int32_t params[] = { gpu_idx ? 0 : 1 };
ggml_set_op_params(result, params, sizeof(params));
return result;
}
算子调用
回到llama_decode_internal中。计算图被构建以后,后续则会被使用ggml_graph_compute_helper进行计算。
ggml_graph_compute_helper会调用ggml_graph_plan评估工作缓冲区的大小,得到一个ggml_cplan(主要成员为work_size,work_data和n_threads)。然后,会使用ggml_graph_compute(graph, &plan)进行计算。
static void ggml_graph_compute_helper(std::vector<uint8_t> & buf, ggml_cgraph * graph, int n_threads) {
struct ggml_cplan plan = ggml_graph_plan(graph, n_threads);
if (plan.work_size > 0) {
buf.resize(plan.work_size);
plan.work_data = buf.data();
}
ggml_graph_compute(graph, &plan);
}
区别于原先的代码,PowerInfer所使用的state_shared中n_threads与n_active均比cplan中的值少1,这应该是由于PowerInfer中有一个单独的线程专门用作GPU Executor。
然后,PowerInfer创建的工作线程所执行函数为ggml_graph_compute_thread_hybrid(区别于ggml_graph_compute_thread),最终完成计算。
int ggml_graph_compute(struct ggml_cgraph * cgraph, struct ggml_cplan * cplan) {
{
GGML_ASSERT(cplan);
GGML_ASSERT(cplan->n_threads > 0);
if (cplan->work_size > 0) {
GGML_ASSERT(cplan->work_data);
}
}
const int n_threads = cplan->n_threads;
#ifdef GGML_USE_HYBRID_THREADING
struct ggml_compute_state_shared state_shared = {
/*.cgraph =*/ cgraph,
/*.cgraph_plan =*/ cplan,
/*.perf_node_start_cycles =*/ 0,
/*.perf_node_start_time_us =*/ 0,
/*.n_threads =*/ n_threads-1,
/*.aic =*/ 0,
/*.n_active =*/ n_threads-1,
/*.node_n =*/ -1,
/*.abort_callback =*/ NULL,
/*.abort_callback_data =*/ NULL,
};
#else
struct ggml_compute_state_shared state_shared = {
/*.cgraph =*/ cgraph,
/*.cgraph_plan =*/ cplan,
/*.perf_node_start_cycles =*/ 0,
/*.perf_node_start_time_us =*/ 0,
/*.n_threads =*/ n_threads,
/*.aic =*/ 0,
/*.n_active =*/ n_threads,
/*.node_n =*/ -1,
/*.abort_callback =*/ NULL,
/*.abort_callback_data =*/ NULL,
};
#endif
struct ggml_compute_state * workers = alloca(sizeof(struct ggml_compute_state)*n_threads);
// create thread pool
if (n_threads > 1) {
for (int j = 1; j < n_threads; ++j) {
workers[j] = (struct ggml_compute_state) {
.thrd = 0,
.ith = j,
.shared = &state_shared,
};
#ifdef GGML_USE_HYBRID_THREADING
const int rc = ggml_thread_create(&workers[j].thrd, NULL, ggml_graph_compute_thread_hybrid, &workers[j]);
#else
const int rc = ggml_thread_create(&workers[j].thrd, NULL, ggml_graph_compute_thread, &workers[j]);
#endif
GGML_ASSERT(rc == 0);
UNUSED(rc);
}
}
workers[0].ith = 0;
workers[0].shared = &state_shared;
const int64_t perf_start_cycles = ggml_perf_cycles();
const int64_t perf_start_time_us = ggml_perf_time_us();
// this is a work thread too
#ifdef GGML_USE_HYBRID_THREADING
int compute_status = (size_t) ggml_graph_compute_thread_hybrid(&workers[0]);
#else
int compute_status = (size_t) ggml_graph_compute_thread(&workers[0]);
#endif
// don't leave affinity set on the main thread
clear_numa_thread_affinity();
// join or kill thread pool
if (n_threads > 1) {
for (int j = 1; j < n_threads; j++) {
const int rc = ggml_thread_join(workers[j].thrd, NULL);
GGML_ASSERT(rc == 0);
}
}
// performance stats (graph)
{
int64_t perf_cycles_cur = ggml_perf_cycles() - perf_start_cycles;
int64_t perf_time_us_cur = ggml_perf_time_us() - perf_start_time_us;
cgraph->perf_runs++;
cgraph->perf_cycles += perf_cycles_cur;
cgraph->perf_time_us += perf_time_us_cur;
GGML_PRINT_DEBUG("%s: perf (%d) - cpu = %.3f / %.3f ms, wall = %.3f / %.3f ms\n",
__func__, cgraph->perf_runs,
(double) perf_cycles_cur / (double) ggml_cycles_per_ms(),
(double) cgraph->perf_cycles / (double) ggml_cycles_per_ms() / (double) cgraph->perf_runs,
(double) perf_time_us_cur / 1000.0,
(double) cgraph->perf_time_us / 1000.0 / cgraph->perf_runs);
}
return compute_status;
}
因此重头戏就在工作线程所执行的ggml_graph_compute_thread_hybrid里面。这是一个比较长的函数,我们来梳理一下里面的流程。
- 主要的函数体是一个
while(true)的循环,计算图的节点会在里面依次得到计算。 - 第0号线程(
state->ith == 0)会进入一条单独的路径。事实上从if (node->backend == GGML_BACKEND_CPU) continue;可以看出这是专门用来负责GPU计算的线程。其会使用一个while (1)循环来等待node->src[0]->is_finish,node->src[1]->is_finish和node->src[2]->is_finish均准备就绪,然后设置参数(params.type = GGML_TASK_COMPUTE)调用ggml_compute_forward进行计算,之后再把node->is_finish置为1。以此往复,直到node_n >= cgraph->n_nodes。 - 其他线程(非0号)是负责执行CPU计算的线程。
- 算子可能有
INIT子任务和FINALIZE子任务,可使用GGML_OP_HAS_INIT[node->op]和GGML_OP_HAS_FINALIZE[node->op]来判断。 - 每个线程每次循环会先执行一遍
atomic_fetch_sub(&state->shared->n_active, 1)。- 最后一个执行到这里(返回值为1)的线程将会负责上一个节点的
FINALIZE子任务(可能是收集结果等),然后分发新任务。分发新任务的过程包括:++node_n。- 等待
src[0],src[1]和src[2]完成。 - 如果有
INIT子任务,执行INIT子任务。 - 如果
n_tasks == 1,说明只有一份任务,直接当场自己执行了,不用交给其他线程。如果有FINALIZE子任务则把FINALIZE也执行了。然后回到++node_n的步骤。 n_tasks不是1,那么重置好state->shared->n_active为n_threads,设置好state->shared->node_n为新的node_n。
atomic_fetch_sub(&state->shared->n_active, 1) == 1判定失败的线程会对state->shared->node_n进行等待,直到其出现变化(值不等于之前拿到的局部变量node_n了)。别忘了分发任务的结尾会设置新的state->shared->node_n,其影响的就是这里。
- 最后一个执行到这里(返回值为1)的线程将会负责上一个节点的
- 无论是否是负责分发任务的线程,都会尝试对当前任务进行计算。
if (node_n >= cgraph->n_nodes) break;:所有节点执行完毕,可以退出最外层的while(true)循环,任务停止。- 设置
ggml_compute_params。这里由于负责执行CPU计算的线程是从state->ith == 1开始的,因此ith要减一。至于nth这里为什么是n_tasks-1,本人依然有疑问。有知道的可联系笔者或在评论区评论。 state->ith < n_tasks的情况下,调用ggml_compute_forward执行分配给自己的计算任务。
- 算子可能有
static thread_ret_t ggml_graph_compute_thread_hybrid(void * data) {
struct ggml_compute_state * state = (struct ggml_compute_state *) data;
const struct ggml_cgraph * cgraph = state->shared->cgraph;
const struct ggml_cplan * cplan = state->shared->cplan;
const int n_threads = state->shared->n_threads;
set_numa_thread_affinity(state->ith, n_threads);
// cpu_set_t mask;
// CPU_ZERO(&mask);
// CPU_SET(state->ith * 2, &mask);
// if (sched_setaffinity(0, sizeof(mask), &mask) == -1) {
// perror("sched_setaffinity");
// }
int node_n = -1;
while (true) {
if (cplan->abort_callback && cplan->abort_callback(cplan->abort_callback_data)) {
state->shared->node_n += 1;
return (thread_ret_t) GGML_EXIT_ABORTED;
}
if (state->ith == 0)
{
// atomic_fetch_sub(&state->shared->n_active, 1);
node_n = -1;
// return 0;
while (1)
{
state->shared->perf_node_start_cycles = ggml_perf_cycles();
state->shared->perf_node_start_time_us = ggml_perf_time_us();
node_n = node_n + 1;
if (node_n >= cgraph->n_nodes)
return 0;
struct ggml_tensor *node = cgraph->nodes[node_n];
if (node->backend == GGML_BACKEND_CPU)
continue;
// uint64_t dbug = 0;
while (1)
{
// dbug++;
int status0 = atomic_load(&node->src[0]->is_finish);
int status1 = 1;
int status2 = 1;
if (node->src[1] != NULL)
status1 = atomic_load(&node->src[1]->is_finish);
if (node->src[2] != NULL)
status2 = atomic_load(&node->src[2]->is_finish);
// if (dbug > 10000000) {
// printf("stuck %s thread %d\n", ggml_get_name(node), n_threads);
// int k;
// scanf("%d", &k);
// }
if (status0 == 1 && status1 == 1 && status2 == 1)
{
break;
}
// else
// busy_wait_cycles(10);
}
struct ggml_compute_params params = {
/*.type =*/GGML_TASK_COMPUTE,
/*.ith =*/0,
/*.nth =*/1,
/*.wsize =*/0,
/*.wdata =*/0,
/*.aic =*/0,
};
// printf("GPU %s\n", ggml_get_name(node));
// cudaDeviceSynchronize();
ggml_compute_forward(¶ms, node);
// cudaDeviceSynchronize();
// ggml_graph_compute_perf_stats_node_gpu(node, state->shared);
ggml_graph_compute_perf_stats_node_gpu(node, state->shared);
// if (strcmp(ggml_get_name(node), "before") == 0)
// printf("%ld\n", ggml_time_us());
atomic_store(&node->is_finish, 1);
}
}
if (atomic_fetch_sub(&state->shared->n_active, 1) == 1) {
// all other threads are finished and spinning
// do finalize and init here so we don't have synchronize again
struct ggml_compute_params params = {
/*.type =*/ GGML_TASK_FINALIZE,
/*.ith =*/ 0,
/*.nth =*/ 0,
/*.wsize =*/ cplan->work_size,
/*.wdata =*/ cplan->work_data,
/*.aic =*/ &state->shared->aic,
};
if (node_n != -1) {
/* FINALIZE */
struct ggml_tensor * node = cgraph->nodes[node_n];
if (GGML_OP_HAS_FINALIZE[node->op]) {
params.nth = ggml_get_n_tasks(node, n_threads);
ggml_compute_forward(¶ms, node);
}
ggml_graph_compute_perf_stats_node(node, state->shared);
atomic_store(&node->is_finish, 1);
}
// distribute new work or execute it direct if 1T
while (++node_n < cgraph->n_nodes) {
GGML_PRINT_DEBUG_5("%s: %d/%d\n", __func__, node_n, cgraph->n_nodes);
struct ggml_tensor * node = cgraph->nodes[node_n];
const int n_tasks = ggml_get_n_tasks(node, n_threads);
state->shared->perf_node_start_cycles = ggml_perf_cycles();
state->shared->perf_node_start_time_us = ggml_perf_time_us();
params.nth = n_tasks;
if (node->backend == GGML_BACKEND_GPU)
continue;
while(1)
{
int status0 = atomic_load(&node->src[0]->is_finish);
int status1 = 1;
int status2 = 1;
if(node->src[1] != NULL)
status1 = atomic_load(&node->src[1]->is_finish);
if(node->src[2] != NULL)
status2 = atomic_load(&node->src[2]->is_finish);
if(status0 == 1 && status1 == 1 && status2 == 1)
break;
// else busy_wait_cycles(10);
}
/* INIT */
if (GGML_OP_HAS_INIT[node->op]) {
params.type = GGML_TASK_INIT;
ggml_compute_forward(¶ms, node);
}
if (n_tasks == 1) {
// TODO: maybe push node_n to the atomic but if other threads see n_tasks is 1,
// they do something more efficient than spinning (?)
params.type = GGML_TASK_COMPUTE;
ggml_compute_forward(¶ms, node);
atomic_store(&node->is_finish, 1);
if (GGML_OP_HAS_FINALIZE[node->op]) {
params.type = GGML_TASK_FINALIZE;
ggml_compute_forward(¶ms, node);
}
ggml_graph_compute_perf_stats_node(node, state->shared);
} else {
break;
}
if (cplan->abort_callback && cplan->abort_callback(cplan->abort_callback_data)) {
break;
}
}
atomic_store(&state->shared->n_active, n_threads);
atomic_store(&state->shared->node_n, node_n);
} else {
// wait for other threads to finish
const int last = node_n;
while (true) {
// TODO: this sched_yield can have significant impact on the performance - either positive or negative
// depending on the workload and the operating system.
// since it is not clear what is the best approach, it should potentially become user-configurable
// ref: https://github.com/ggerganov/ggml/issues/291
#if defined(GGML_USE_ACCELERATE) || defined(GGML_USE_OPENBLAS)
sched_yield();
#endif
node_n = atomic_load(&state->shared->node_n);
if (node_n != last) break;
};
}
// check if we should stop
if (node_n >= cgraph->n_nodes) break;
/* COMPUTE */
struct ggml_tensor * node = cgraph->nodes[node_n];
const int n_tasks = ggml_get_n_tasks(node, n_threads);
struct ggml_compute_params params = {
/*.type =*/ GGML_TASK_COMPUTE,
/*.ith =*/ state->ith-1,
/*.nth =*/ n_tasks-1,
/*.wsize =*/ cplan->work_size,
/*.wdata =*/ cplan->work_data,
/*.aic =*/ &state->shared->aic,
};
if (state->ith < n_tasks) {
ggml_compute_forward(¶ms, node);
}
}
return GGML_EXIT_SUCCESS;
}
ggml_compute_forward会负责根据tensor->op去调用具体的算子。
static void ggml_compute_forward(struct ggml_compute_params * params, struct ggml_tensor * tensor) {
GGML_ASSERT(params);
if (tensor->op == GGML_OP_NONE) {
return;
}
#ifdef GGML_USE_CUBLAS
bool skip_cpu = ggml_cuda_compute_forward(params, tensor);
if (skip_cpu) {
return;
}
// Make sure src[0] (weight for binary ops) is on CPU to avoid any weight transfer
GGML_ASSERT((tensor->src[0] == NULL || tensor->src[0]->backend == GGML_BACKEND_CPU) && "weight should be on the CPU to compute on the CPU");
#endif // GGML_USE_CUBLAS
switch (tensor->op) {
case GGML_OP_DUP:
{
ggml_compute_forward_dup(params, tensor->src[0], tensor);
} break;
case GGML_OP_ADD:
{
ggml_compute_forward_add(params, tensor->src[0], tensor->src[1], tensor);
} break;
case GGML_OP_ADD1:
{
ggml_compute_forward_add1(params, tensor->src[0], tensor->src[1], tensor);
} break;
case GGML_OP_ACC:
{
ggml_compute_forward_acc(params, tensor->src[0], tensor->src[1], tensor);
} break;
case GGML_OP_SUB:
{
ggml_compute_forward_sub(params, tensor->src[0], tensor->src[1], tensor);
} break;
case GGML_OP_MUL:
{
ggml_compute_forward_mul(params, tensor->src[0], tensor->src[1], tensor);
} break;
case GGML_OP_DIV:
{
ggml_compute_forward_div(params, tensor->src[0], tensor->src[1], tensor);
} break;
// Other cases...
// -- snip --
}
}
额外地,我们注意ggml_compute_foward的开头:如果使用了CUBLAS,那么就转而调用CUDA实现的算子(ggml_cuda_compute_forward)。
static void ggml_compute_forward(struct ggml_compute_params * params, struct ggml_tensor * tensor) {
GGML_ASSERT(params);
if (tensor->op == GGML_OP_NONE) {
return;
}
#ifdef GGML_USE_CUBLAS
bool skip_cpu = ggml_cuda_compute_forward(params, tensor);
if (skip_cpu) {
return;
}
// Make sure src[0] (weight for binary ops) is on CPU to avoid any weight transfer
GGML_ASSERT((tensor->src[0] == NULL || tensor->src[0]->backend == GGML_BACKEND_CPU) && "weight should be on the CPU to compute on the CPU");
#endif // GGML_USE_CUBLAS
switch (tensor->op) {
case GGML_OP_DUP:
{
ggml_compute_forward_dup(params, tensor->src[0], tensor);
} break;
// Other cases...
// -- snip --
}
}
在ggml_cuda_compute_forward中,会根据tensor->op去调用具体的CUDA算子。
bool ggml_cuda_compute_forward(struct ggml_compute_params * params, struct ggml_tensor * tensor) {
if (!g_cublas_loaded) return false;
ggml_cuda_func_t func;
const bool src0_on_device = tensor->src[0] != nullptr && (tensor->src[0]->backend != GGML_BACKEND_CPU);
const bool any_on_device = tensor->backend == GGML_BACKEND_GPU || src0_on_device
|| (tensor->src[1] != nullptr && tensor->src[1]->backend == GGML_BACKEND_GPU);
// when src0 (weights) is not on device, we compute on CPU with sparsity
if (!src0_on_device && (tensor->op == GGML_OP_MUL_MAT_SPARSE || tensor->op == GGML_OP_AXPY)
|| !any_on_device && tensor->op != GGML_OP_MUL_MAT) {
return false;
}
if (tensor->op == GGML_OP_MUL_MAT) {
if (tensor->src[0]->ne[3] != tensor->src[1]->ne[3]) {
#ifndef NDEBUG
fprintf(stderr, "%s: cannot compute %s: src0->ne[3] = %d, src1->ne[3] = %d - fallback to CPU\n", __func__, tensor->name, tensor->src[0]->ne[3], tensor->src[1]->ne[3]);
#endif
return false;
}
}
switch (tensor->op) {
case GGML_OP_REPEAT:
func = ggml_cuda_repeat;
break;
case GGML_OP_GET_ROWS:
func = ggml_cuda_get_rows;
break;
case GGML_OP_DUP:
func = ggml_cuda_dup;
break;
case GGML_OP_ADD:
func = ggml_cuda_add;
break;
case GGML_OP_MUL:
func = ggml_cuda_mul;
break;
case GGML_OP_UNARY:
switch (ggml_get_unary_op(tensor)) {
case GGML_UNARY_OP_GELU:
func = ggml_cuda_gelu;
break;
case GGML_UNARY_OP_SILU:
func = ggml_cuda_silu;
break;
case GGML_UNARY_OP_RELU:
func = ggml_cuda_relu;
break;
default:
return false;
} break;
case GGML_OP_NORM:
func = ggml_cuda_norm;
break;
case GGML_OP_RMS_NORM:
func = ggml_cuda_rms_norm;
break;
case GGML_OP_MUL_MAT:
if (!any_on_device && !ggml_cuda_can_mul_mat(tensor->src[0], tensor->src[1], tensor)) {
return false;
}
func = ggml_cuda_mul_mat;
break;
case GGML_OP_MUL_MAT_SPARSE:
if (!src0_on_device && !ggml_cuda_can_mul_mat(tensor->src[0], tensor->src[1], tensor)) {
return false;
}
func = ggml_cuda_mul_mat_sparse;
break;
case GGML_OP_AXPY:
func = ggml_cuda_axpy;
break;
// Other cases...
// -- snip --
default:
return false;
}
if (params->ith != 0) {
return true;
}
if (params->type == GGML_TASK_INIT || params->type == GGML_TASK_FINALIZE) {
return true;
}
func(tensor->src[0], tensor->src[1], tensor);
// CUDA_CHECK(cudaDeviceSynchronize());
return true;
}
以ggml_cuda_mul_mat_sparse为例,其会根据类型继续下调。
static void ggml_cuda_mul_mat_sparse(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
GGML_ASSERT(dst->src[2] != NULL && "dst->src[2] must be present for sparse matrix multiplication");
if (src1->ne[1] == 1 && src0->ne[0] % GGML_CUDA_DMMV_X == 0) {
switch(src0->type) {
case GGML_TYPE_F16:
ggml_cuda_op_mul_mat(src0, src1, dst, ggml_cuda_op_mul_mat_vec_sparse_dequantized, false);
break;
case GGML_TYPE_Q4_0:
ggml_cuda_op_mul_mat(src0, src1, dst, ggml_cuda_op_mul_mat_vec_sparse_q, true);
break;
default:
GGML_ASSERT(false && "unsupported type for sparse matrix multiplication");
}
} else {
ggml_cuda_op_mul_mat(src0, src1, dst, ggml_cuda_op_mul_mat_batch_sparse, false);
}
}
至此,后续便能调用到具体负责计算的算子。模型加载以后,计算图的构建一直到算子的调用的大致流程也结束了。
支持 ☕️
如果发现内容有纰漏或错误,可以通过邮箱hangyu.yuan@qq.com联系我或直接在下方评论告诉我,谢谢。
我的GitHub主页。