PowerInfer源码解析(一):模型加载
最近开始着手研究PowerInfer,但看了下网上似乎还没有针对PowerInfer的代码解析,因此本人打算自己动手。
相关
背景
PowerInfer是由著名的同校同院系实验室(IPADS)推出的在配备单个消费级GPU的个人电脑(PC)上进行高速大型语言模型(LLM)推理的引擎。PowerInfer设计的关键在于利用LLM推理中固有的高局部性特征,该特征表现为神经元激活的幂律分布(a power-law distribution in neuron activation)。该分布表明,一小部分神经元,被称为热神经元(hot neurons),在不同的输入中始终保持激活状态,而大多数神经元(冷神经元,cold neurons)则根据特定输入发生变化。PowerInfer利用这一见解设计了一个GPU-CPU混合推理引擎:热神经元预先加载到GPU中以便快速访问,而冷神经元则在CPU上进行计算,从而显著减少了GPU内存需求和CPU-GPU之间的数据传输。PowerInfer还集成了自适应预测器(adaptive predictors)和神经元感知稀疏算子(neuron-aware sparse operators),优化了神经元激活和计算稀疏性的效率。评估结果显示,PowerInfer在单个NVIDIA RTX 4090 GPU上对各种LLM(包括OPT-175B)实现了平均每秒生成13.20个token,峰值达到29.08个token/s,仅比顶级服务器级A100 GPU低18%。同时,PowerInfer的性能远超llama.cpp,最高可达11.69倍,并保持模型精度。
说明
- PowerInfer的仓库地址。
- PowerInfer基于llama.cpp的Commit
6bb4908a17150b49373b5f977685b2e180a04f6f进行修改。llama.cpp的代码量不少,维护较勤,网上也有很多解析,因此不是本文要介绍的重点。本文主要介绍的是PowerInfer基于llama.cpp的修改部分,对llama.cpp的原有部分不会有过多解释。 - 本文所使用来对比的PowerInfer Commit:
6ae7e06dbe1032ec103e1a08ce126b3d1ed2d6e7<-->6bb4908a17150b49373b5f977685b2e180a04f6f
GGML
整个llama.cpp项目可以分为两部分:底层的张量库GGML(C语言),和应用层的模型推理代码(C++语言)。严格来说,GGML是一个独立的项目,但在实际开发中,GGML被完整包含在llama.cpp项目中(工程目录下的ggml*文件)一起开发,并反馈合并给上游的原仓库。
ggml 是一个用 C 和 C++ 编写、专注于 Transformer 架构模型推理的机器学习库。该项目完全开源,处于活跃的开发阶段,开发社区也在不断壮大。ggml 和 PyTorch、TensorFlow 等机器学习库比较相似,但由于目前处于开发的早期阶段,一些底层设计仍在不断改进中。
关于ggml的使用,可参考这篇blog以有一个基本的了解。
正文
目光转向程序的入口,example/main/main.cpp:main。经过一堆乱七八糟的参数解析,我们把目光锁定在这里:
// load the model and apply lora adapter, if any
LOG("%s: load the model and apply lora adapter, if any\n", __func__);
std::tie(model, ctx) = llama_init_from_gpt_params(params);
if (sparams.cfg_scale > 1.f) {
struct llama_context_params lparams = llama_context_params_from_gpt_params(params);
ctx_guidance = llama_new_context_with_model(model, lparams);
}
点进这里调用的llama_init_from_gpt_params,我们可以看到更改的部分。原先,cparams是在llama_load_model_from_file之后才生成的,而这里被提到了前面,并作为参数传给了llama_load_model_from_file_with_context,说明PowerInfer的初始化过程对cparams有额外的需求。
std::tuple<struct llama_model *, struct llama_context *> llama_init_from_gpt_params(gpt_params & params) {
auto mparams = llama_model_params_from_gpt_params(params);
auto cparams = llama_context_params_from_gpt_params(params);
llama_model * model = llama_load_model_from_file_with_context(params.model.c_str(), mparams, &cparams);
if (model == NULL) {
fprintf(stderr, "%s: error: failed to load model '%s'\n", __func__, params.model.c_str());
return std::make_tuple(nullptr, nullptr);
}
我们可以看到,原先的llama_load_model_from_file接口得到保留,其也是调到了PowerInfer新加的llama_load_model_from_file_with_context接口,只要把额外的cparams参数设置为nullptr即可。
struct llama_model * llama_load_model_from_file(
const char * path_model,
struct llama_model_params params) {
return llama_load_model_from_file_with_context(path_model, params, nullptr);
}
而llama_load_model_from_file_with_context则是替代了原先接口的功能。额外地,其把cparams参数又传给了llama_model_load。
struct llama_model * llama_load_model_from_file_with_context(
const char * path_model,
struct llama_model_params params,
struct llama_context_params * cparams
) {
ggml_time_init();
llama_model * model = new llama_model;
unsigned cur_percentage = 0;
if (params.progress_callback == NULL) {
params.progress_callback_user_data = &cur_percentage;
params.progress_callback = [](float progress, void * ctx) {
unsigned * cur_percentage_p = (unsigned *) ctx;
unsigned percentage = (unsigned) (100 * progress);
while (percentage > *cur_percentage_p) {
*cur_percentage_p = percentage;
LLAMA_LOG_INFO(".");
if (percentage >= 100) {
LLAMA_LOG_INFO("\n");
}
}
};
}
if (!llama_model_load(path_model, *model, params, cparams)) {
LLAMA_LOG_ERROR("%s: failed to load model\n", __func__);
delete model;
return nullptr;
}
return model;
}
进入llama_model_load里面,我们观察到PowerInfer先使用params初始化了llama_model_loader,该类型对象在构造时会读取fname指定的gguf文件,解析文件的内容,并根据文件内容设置一些信息。
static bool llama_model_load(const std::string & fname, llama_model & model, const llama_model_params & params, const llama_context_params * cparams) {
try {
llama_model_loader ml(fname, params.use_mmap);
if (ml.sparse_deriv == GGML_SPARSE_INFERENCE) {
LLAMA_LOG_INFO("%s: PowerInfer model loaded. Sparse inference will be used.\n", __func__);
}
model.hparams.vocab_only = params.vocab_only;
model.sparse_deriv = ml.sparse_deriv;
llm_load_arch (ml, model);
llm_load_hparams(ml, model);
llm_load_vocab (ml, model);
llm_load_print_meta(ml, model);
if (model.hparams.n_vocab != model.vocab.id_to_token.size()) {
throw std::runtime_error("vocab size mismatch");
}
if (params.vocab_only) {
LLAMA_LOG_INFO("%s: vocab only - skipping tensors\n", __func__);
return true;
}
if (llama_use_sparse_inference(&model)) {
if (params.n_gpu_layers > 0) {
LLAMA_LOG_WARN("%s: sparse inference ignores n_gpu_layers, you can use --vram-budget option instead\n", __func__);
return false;
}
#if defined GGML_USE_CUBLAS
llama_set_vram_budget(params.vram_budget_gb, params.main_gpu);
#endif
llm_load_sparse_model_tensors(
ml, model, cparams, params.main_gpu, vram_budget_bytes, params.reset_gpu_index, params.disable_gpu_index,
params.use_mlock, params.progress_callback, params.progress_callback_user_data
);
} else {
llm_load_tensors(
ml, model, params.n_gpu_layers, params.main_gpu, params.tensor_split, params.use_mlock,
params.progress_callback, params.progress_callback_user_data
);
}
} catch (const std::exception & err) {
LLAMA_LOG_ERROR("error loading model: %s\n", err.what());
return false;
}
return true;
}
其中,llm_load_hparams中添加了对sparse_pred_threshold的获取和设置。
static void llm_load_hparams(
llama_model_loader & ml,
llama_model & model) {
// -- snip --
if (gguf_get_sparse_deriv(ctx)) {
// read sparse threshold override if sparse deriv is enabled
GGUF_GET_KEY(ctx, hparams.sparse_pred_threshold, gguf_get_val_f32, GGUF_TYPE_FLOAT32, false, kv(LLM_KV_SPARSE_THRESHOLD));
if (getenv("LLAMA_SPARSE_PRED_THRESHOLD"))
hparams.sparse_pred_threshold = (float)atof(getenv("LLAMA_SPARSE_PRED_THRESHOLD"));
}
// -- snip --
}
我们注意到llama_model_load代码中使用了ml.sparse_deriv是否为GGML_SPARSE_INFERENCE来判断了是否要使用PowerInfer(包括llama_use_sparse_inference函数里面也是判断的model里的sparse_deriv成员),那么这个sparse_deriv是如何被读取和设置的呢?
查询gguf文件的格式如下。

我们可以注意到,文件的前四个Bytes是magic number。
再来看代码,结果就很清晰了。原来PowerInfer为这4个Bytes多增加了一种合法的magic number解析(GGUF_POWERINFER_MAGIC),并根据此来判断是否该启用PowerInfer的sparse inference模式。
struct gguf_context * gguf_init_from_file(const char * fname, struct gguf_init_params params) {
FILE * file = fopen(fname, "rb");
if (!file) {
return NULL;
}
// offset from start of file
size_t offset = 0;
char magic[4];
enum ggml_sparse_deriv sparse_deriv;
// check the magic before making allocations
{
gguf_fread_el(file, &magic, sizeof(magic), &offset);
if (strncmp(magic, GGUF_MAGIC, sizeof(magic)) == 0) {
sparse_deriv = GGML_DENSE_INFERENCE;
} else if (strncmp(magic, GGUF_POWERINFER_MAGIC, sizeof(magic)) == 0) {
sparse_deriv = GGML_SPARSE_INFERENCE;
} else {
fprintf(stderr, "%s: invalid magic characters %s.\n", __func__, magic);
fclose(file);
return NULL;
}
}
bool ok = true;
struct gguf_context * ctx = GGML_ALIGNED_MALLOC(sizeof(struct gguf_context));
ctx->sparse_deriv = sparse_deriv;
// Other codes that read and parse the GGUF file.
// -- snip --
}
回到之前的llama_model_load函数。如果是GGML_SPARSE_INFERENCE,那么PowerInfer会使用llm_load_sparse_model_tensors来加载张量。
这是一个比较长的函数。简单而言,我们可以把流程概括为:
- 计算内存需求,创建并初始化
ggml上下文。 - 根据是否加载了 GPU 库(如 cuBLAS 或 OpenCL),选择将一部分计算分配给 GPU。
- 函数根据模型的架构不同,对每种架构进行不同的张量分配。
- 调用
alloc.flush()来将分配的层同步到 GPU(设置backend以及减budget)。 - 通过
ml.load_all_data将将模型的所有数据加载到内存中。 - 如果 cparams 存在,分配 KV Cache(的空间)。
- 调用
llm_load_gpu_split来处理 FFN 网络的分片和分配。
static void llm_load_sparse_model_tensors(
llama_model_loader & ml,
llama_model & model,
const llama_context_params * cparams,
int main_gpu,
long int vram_budget_bytes,
bool reset_gpu_index,
bool disable_ffn_split,
bool use_mlock,
llama_progress_callback progress_callback,
void * progress_callback_user_data) {
model.t_start_us = ggml_time_us();
auto & ctx = model.ctx;
auto & hparams = model.hparams;
size_t ctx_size;
size_t mmapped_size;
ml.calc_sizes(ctx_size, mmapped_size);
LLAMA_LOG_INFO("%s: ggml ctx size = %7.2f MB\n", __func__, ctx_size/1024.0/1024.0);
// create the ggml context
{
model.buf.resize(ctx_size);
if (use_mlock) {
model.mlock_buf.init (model.buf.data);
model.mlock_buf.grow_to(model.buf.size);
}
struct ggml_init_params params = {
/*.mem_size =*/ model.buf.size,
/*.mem_buffer =*/ model.buf.data,
/*.no_alloc =*/ ml.use_mmap,
};
model.ctx = ggml_init(params);
if (!model.ctx) {
throw std::runtime_error(format("ggml_init() failed"));
}
}
(void) main_gpu;
enum ggml_backend_type llama_backend_offload = GGML_BACKEND_CPU;
enum ggml_backend_type llama_backend_offload_split = GGML_BACKEND_CPU;
#ifdef GGML_USE_CUBLAS
if (ggml_cublas_loaded()) {
LLAMA_LOG_INFO("%s: using " GGML_CUDA_NAME " for GPU acceleration\n", __func__);
ggml_cuda_set_main_device(main_gpu);
llama_backend_offload = GGML_BACKEND_GPU;
llama_backend_offload_split = GGML_BACKEND_GPU_SPLIT;
}
#elif defined(GGML_USE_CLBLAST)
LLAMA_LOG_INFO("%s: using OpenCL for GPU acceleration\n", __func__);
llama_backend_offload = GGML_BACKEND_GPU;
llama_backend_offload_split = GGML_BACKEND_GPU;
#endif
buffered_tensor_allocator alloc(ml, ctx, hparams);
uint32_t current_layer = 0;
auto create_tensor = [&alloc, ¤t_layer] (
const std::pair<std::string, llm_tensor> & tn,
const std::vector<int64_t> & ne) -> ggml_tensor * {
return alloc.buffered_alloc(tn.first, tn.second, ne, current_layer);
};
{
const int64_t n_embd = hparams.n_embd;
const int64_t n_embd_gqa = hparams.n_embd_gqa();
const int64_t n_layer = hparams.n_layer;
const int64_t n_vocab = hparams.n_vocab;
const auto tn = LLM_TN(model.arch);
switch (model.arch) {
case LLM_ARCH_LLAMA:
case LLM_ARCH_REFACT:
case LLM_ARCH_BAMBOO:
{
model.tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab});
// output
{
model.output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd});
model.output = create_tensor(tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab});
}
const uint32_t n_ff = hparams.n_ff;
model.layers.resize(n_layer);
for (uint32_t &i = current_layer; i < n_layer; ++i) {
auto & layer = model.layers[i];
layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd});
layer.wq = create_tensor(tn(LLM_TENSOR_ATTN_Q, "weight", i), {n_embd, n_embd});
layer.wk = create_tensor(tn(LLM_TENSOR_ATTN_K, "weight", i), {n_embd, n_embd_gqa});
layer.wv = create_tensor(tn(LLM_TENSOR_ATTN_V, "weight", i), {n_embd, n_embd_gqa});
layer.wo = create_tensor(tn(LLM_TENSOR_ATTN_OUT, "weight", i), {n_embd, n_embd});
layer.ffn_norm = create_tensor(tn(LLM_TENSOR_FFN_NORM, "weight", i), {n_embd});
layer.ffn_gate = create_tensor(tn(LLM_TENSOR_FFN_GATE, "weight", i), {n_embd, n_ff});
layer.ffn_down_t = create_tensor(tn(LLM_TENSOR_FFN_DOWN_T, "weight", i), {n_embd, n_ff});
layer.mlp_pre_w1 = create_tensor(tn(LLM_TENSOR_MLP_PRED_FC1, "weight", i), {n_embd, GGML_NE_WILDCARD});
layer.mlp_pre_w2 = create_tensor(tn(LLM_TENSOR_MLP_PRED_FC2, "weight", i), {GGML_NE_WILDCARD, n_ff});
layer.ffn_up = create_tensor(tn(LLM_TENSOR_FFN_UP, "weight", i), {n_embd, n_ff});
}
} break;
case LLM_ARCH_FALCON:
{
model.tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab});
// output
{
model.output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd});
model.output_norm_b = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "bias"), {n_embd});
model.output = create_tensor(tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab});
}
const uint32_t n_ff = hparams.n_ff;
model.layers.resize(n_layer);
for (uint32_t &i = current_layer; i < n_layer; ++i) {
auto & layer = model.layers[i];
layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd});
layer.attn_norm_b = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "bias", i), {n_embd});
if (gguf_find_tensor(ml.ctx_gguf, tn(LLM_TENSOR_ATTN_NORM_2, "weight", i).first.c_str()) >= 0) {
layer.attn_norm_2 = create_tensor(tn(LLM_TENSOR_ATTN_NORM_2, "weight", i), {n_embd});
layer.attn_norm_2_b = create_tensor(tn(LLM_TENSOR_ATTN_NORM_2, "bias", i), {n_embd});
}
layer.wqkv = create_tensor(tn(LLM_TENSOR_ATTN_QKV, "weight", i), {n_embd, n_embd + 2*n_embd_gqa});
layer.wo = create_tensor(tn(LLM_TENSOR_ATTN_OUT, "weight", i), {n_embd, n_embd});
layer.ffn_down_t = create_tensor(tn(LLM_TENSOR_FFN_DOWN_T, "weight", i), {n_embd, n_ff});
layer.mlp_pre_w1 = create_tensor(tn(LLM_TENSOR_MLP_PRED_FC1, "weight", i), {n_embd, GGML_NE_WILDCARD});
layer.mlp_pre_w2 = create_tensor(tn(LLM_TENSOR_MLP_PRED_FC2, "weight", i), {GGML_NE_WILDCARD, n_ff});
layer.ffn_up = create_tensor(tn(LLM_TENSOR_FFN_UP, "weight", i), {n_embd, n_ff});
}
} break;
default:
throw std::runtime_error("unknown architecture");
}
}
model.n_gpu_layers = alloc.flush();
LLAMA_LOG_INFO("%s: offloaded layers from VRAM budget(%ld bytes): %d/%d\n", __func__, vram_budget_bytes, model.n_gpu_layers, hparams.n_layer);
// print memory requirements
{
// this is the total memory required to run the inference
size_t mem_required = ctx_size + mmapped_size;
LLAMA_LOG_INFO("%s: mem required = %7.2f MB\n", __func__, mem_required / 1024.0 / 1024.0);
#if defined(GGML_USE_CUBLAS) || defined(GGML_USE_CLBLAST)
LLAMA_LOG_INFO("%s: VRAM used: %.2f MB\n", __func__, alloc.vram_allocated_bytes / 1024.0 / 1024.0);
#endif
}
// populate `tensors_by_name`
for (int i = 0; i < ml.n_tensors; ++i) {
struct ggml_tensor * cur = ggml_get_tensor(ctx, ml.get_tensor_name(i));
model.tensors_by_name.emplace_back(ggml_get_name(cur), cur);
}
ml.load_all_data(ctx, progress_callback, progress_callback_user_data, use_mlock ? &model.mlock_mmap : NULL);
if (progress_callback) {
progress_callback(1.0f, progress_callback_user_data);
}
model.mapping = std::move(ml.mapping);
// Reserve KV cache in VRAM
if (cparams != NULL) {
llama_reserve_model_kv_cache(&model, cparams);
}
// Offload FFN segments to GPU if possible
model.ffn_offloaded_bytes = llm_load_gpu_split(ml, model, reset_gpu_index, disable_ffn_split || !alloc.tensor_offload_complete);
// loading time will be recalculate after the first eval, so
// we take page faults deferred by mmap() into consideration
model.t_load_us = ggml_time_us() - model.t_start_us;
}
重点看一下最后的llm_load_gpu_split。其主要调用了llm_load_gpu_split_with_budget和llama_model_offload_ffn_split。其中llm_load_gpu_split_with_budget主要负责加载GPU Index(即哪些计算被卸载到GPU上),llama_model_offload_ffn_split则负责根据GPU Index把每层的Feed Forward层按需加载到GPU上。
static size_t llm_load_gpu_split(llama_model_loader & ml, llama_model & model, bool no_cache, bool no_offload) {
#if defined (GGML_USE_CUBLAS)
if (!ggml_cublas_loaded()) {
throw std::runtime_error(format("cannot offload to GPU: " GGML_CUDA_NAME " not loaded"));
}
if (!no_offload && !llm_load_gpu_split_with_budget(ml, model, vram_budget_bytes, no_cache)) {
LLAMA_LOG_ERROR("%s: error: failed to generate gpu split, an empty one will be used\n", __func__);
}
#endif
// Apply GPU index and split FFNs to GPU
size_t ffn_offloaded_bytes = llama_model_offload_ffn_split(&model);
LLAMA_LOG_INFO("%s: offloaded %.2f MiB of FFN weights to GPU\n", __func__, ffn_offloaded_bytes / 1024.0 / 1024.0);
return ffn_offloaded_bytes;
}
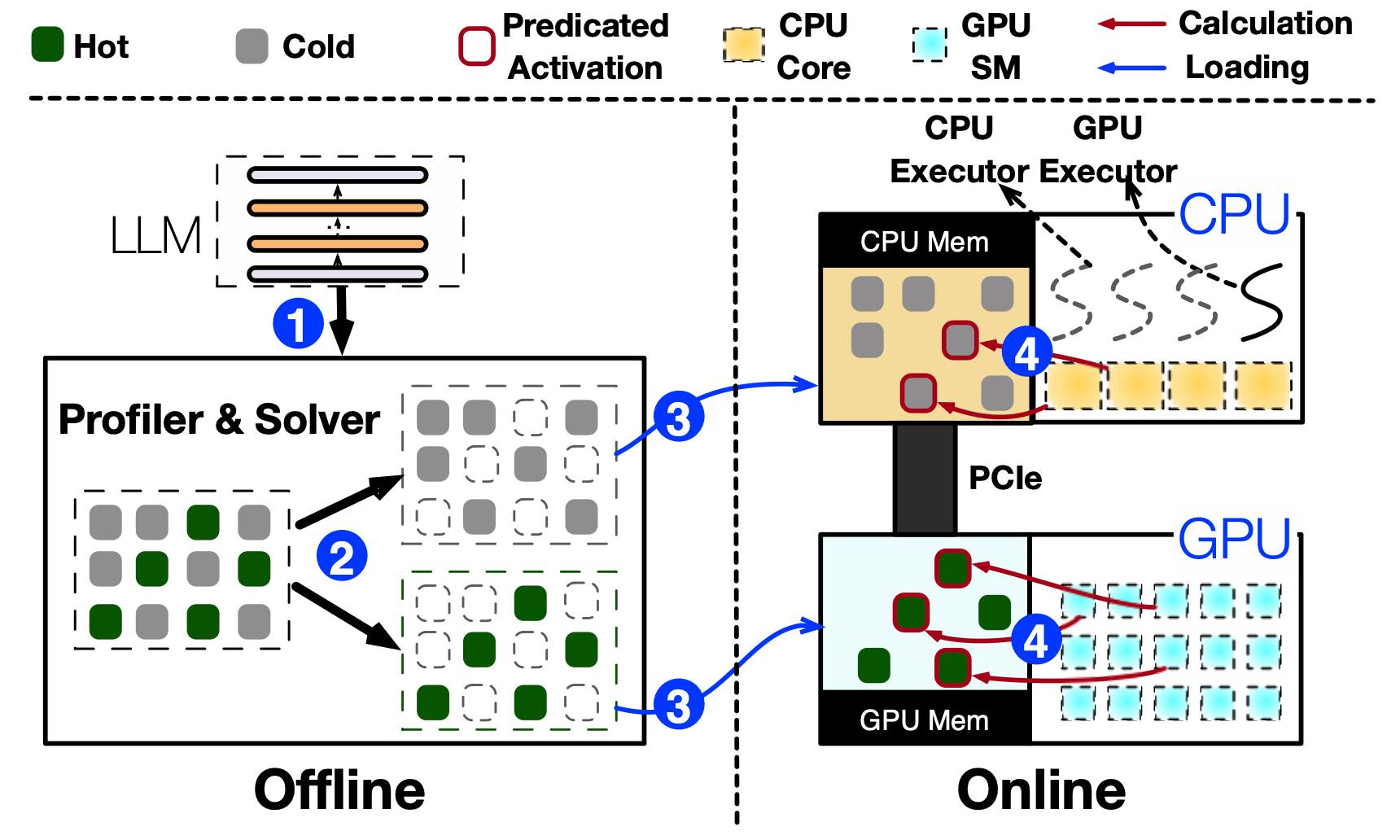
llm_load_gpu_split_with_budget会尝试加载ml.file.fname + ".generated.gpuidx"文件,如果文件不存在则调用python脚本生成一个该文件。脚本的主要作用是通过整数线性规划(具体算法可见论文),得出应该把哪些计算卸载到GPU上。其中,脚本会得到gpu_idx和gpu_bucket。
gpu_idx是一个布尔型(0/1)的张量,用于指示哪些神经元(或张量的部分)会被分配到 GPU 上。它的每个元素与对应层的激活数据(神经元)一一对应。如果某个位置的值为 1,则表示该神经元需要分配到 GPU;如果值为 0,则表示该神经元不在 GPU 上。gpu_bucket是一个表示在 GPU 上实际存储的神经元索引的有序列表(数组)。它仅包含那些被选中要放置到 GPU 上的神经元索引,并且通常是有序的。这种方式便于在 GPU 内存中高效存储和查找。
最后,通过对.gpuidx文件的加载,gpu_idx和gpu_bucket信息会被加载到model的layer中(顺便计算了个model_layer.gpu_offload_ratio)。
int load_gpu_idx_for_model(llama_model * model) {
int n_layers = model->layers.size();
// TODO: assert fp is at the end of headers
if (n_tensors != n_layers * 2) {
LLAMA_LOG_ERROR("%s: error: the number of gpu splits does not match the layer of model\n", __func__);
return 1;
}
LLAMA_LOG_INFO("%s: applying gpu_idx adapter from '%s' - please wait ...\n", __func__, fname.c_str());
const int64_t t_start_mlp_us = ggml_time_us();
for (int il = 0; il < n_layers; il++) {
llama_layer &model_layer = model->layers[il];
ggml_tensor * gpu_idx = idx_loader->get_tensor_meta(il*2);
ggml_tensor * gpu_bucket = idx_loader->get_tensor_meta(il*2+1);
if (gpu_idx == nullptr || gpu_bucket == nullptr) {
LLAMA_LOG_ERROR("%s: error: failed to load gpu index or bucket\n", __func__);
return 1;
}
model_layer.gpu_idx = idx_loader->create_tensor_for(ctx_meta, gpu_idx, GGML_BACKEND_CPU);
model_layer.gpu_bucket = idx_loader->create_tensor_for(ctx_meta, gpu_bucket, GGML_BACKEND_CPU);
}
llama_progress_callback cb = [](float progress, void *ctx) {
LLAMA_LOG_INFO(".");
};
idx_loader->load_all_data(ctx_meta, cb, nullptr, nullptr);
for (int il = 0; il < n_layers; il++) {
llama_layer &model_layer = model->layers[il];
ggml_tensor * gpu_idx = model_layer.gpu_idx;
ggml_tensor * gpu_bucket = model_layer.gpu_bucket;
int64_t gpu_neurons = sum_gpu_index(gpu_idx);
model_layer.gpu_offload_ratio = (double)gpu_neurons / gpu_idx->ne[0];
if (gpu_neurons == 0 || gpu_neurons == gpu_idx->ne[0]) {
// no hybrid inference for this layer, unset gpu_bucket
model_layer.gpu_bucket = NULL;
// TODO: maybe can also unset gpu_idx
} else {
#if defined(GGML_USE_CUBLAS)
ggml_set_backend(gpu_bucket, GGML_BACKEND_GPU);
ggml_cuda_transform_tensor(gpu_bucket->data, gpu_bucket);
#else
GGML_ASSERT(false && "cublas is not enabled");
#endif
}
}
const int64_t t_mlp_us = ggml_time_us() - t_start_mlp_us;
LLAMA_LOG_INFO(" done (%.2f ms)\n", t_mlp_us / 1000.0);
return 0;
}
至于llama_model_offload_ffn_split,最终会对每一层调用slice_ffn_mat_to_gpu来根据gpu_bucket把ffn_gate、ffn_up和ffn_down卸载到GPU上。
size_t slice_ffn_mat_to_gpu(llama_layer & layer) {
std::vector<uint8_t> work_buffer;
ggml_tensor * gpu_idx = layer.gpu_idx;
ggml_tensor * gpu_bucket = layer.gpu_bucket;
size_t offloaded_bytes = 0;
if (layer.gpu_offload_ratio == 0.) {
return 0;
}
GGML_ASSERT((layer.gpu_bucket != NULL) == (layer.gpu_offload_ratio < 1.0));
if (layer.ffn_gate) {
layer.ffn_gate_gpu = create_striped_mat_to_gpu(layer.ffn_gate, gpu_bucket);
offloaded_bytes += ggml_nbytes(layer.ffn_gate_gpu);
}
layer.ffn_up_gpu = create_striped_mat_to_gpu(layer.ffn_up, gpu_bucket);
offloaded_bytes += ggml_nbytes(layer.ffn_up_gpu);
layer.ffn_down_gpu = create_striped_mat_to_gpu(layer.ffn_down_t, gpu_bucket);
offloaded_bytes += ggml_nbytes(layer.ffn_down_gpu);
return offloaded_bytes;
}
size_t offload_ffn_split(llama_model * model) {
LLAMA_LOG_INFO("%s: applying augmentation to model - please wait ...\n", __func__);
const int64_t t_start_aug_us = ggml_time_us();
std::vector<uint8_t> work_buffer;
// Set sparsity threshold via global virables
sparse_pred_threshold = model->hparams.sparse_pred_threshold;
#if defined (GGML_USE_CUBLAS)
ggml_cuda_set_device_constants(model->hparams.sparse_pred_threshold);
#endif
// load gpu_idx and slice mat to gpu
size_t offloaded_bytes = 0;
for (llama_layer &model_layer : model -> layers) {
// gpu_idx load
if (model_layer.gpu_idx == NULL && model_layer.gpu_bucket == NULL) {
ggml_tensor * gpu_idx = ggml_new_tensor_1d(aux_ctx, GGML_TYPE_I32, model_layer.mlp_pre_w2 -> ne[1]);
ggml_set_zero(gpu_idx);
model_layer.gpu_idx = gpu_idx;
ggml_tensor * gpu_bucket = ggml_new_tensor_1d(aux_ctx, GGML_TYPE_I32, 0);
model_layer.gpu_bucket = gpu_bucket;
}
offloaded_bytes += slice_ffn_mat_to_gpu(model_layer);
LLAMA_LOG_INFO(".");
}
LLAMA_LOG_INFO(" done (%.2f ms)\n", (ggml_time_us() - t_start_aug_us) / 1000.0);
return offloaded_bytes;
}
点进create_striped_mat_to_gpu,我们还可以看到weights是如何根据gpu_bucket被卸载到GPU上的。简单说,gpu_bucket中存储的是host_i,据此我们找到host中的(char *)(src -> data) + host_i * row_data_size位置来将数据一行一行copy到GPU上。
ggml_tensor * create_striped_mat_to_gpu(struct ggml_tensor *src, struct ggml_tensor * gpu_bucket) {
#ifdef GGML_USE_CUBLAS
if (gpu_bucket == NULL) {
// offload the whole tensor to gpu
ggml_set_backend(src, GGML_BACKEND_GPU);
ggml_cuda_transform_tensor(src->data, src);
return src;
}
int64_t row_len = src->ne[0];
int64_t gpu_rows = gpu_bucket->ne[0];
GGML_ASSERT(0 < gpu_rows && gpu_rows <= src->ne[1]);
ggml_set_no_alloc(aux_ctx, true);
ggml_tensor * gpu_dst = ggml_new_tensor_2d(aux_ctx, src->type, row_len, gpu_rows);
ggml_set_backend(gpu_dst, GGML_BACKEND_GPU);
ggml_cuda_alloc_tensor(gpu_dst);
// init two 1d views on host and device
ggml_tensor * host_mat_row = ggml_new_tensor_1d(aux_ctx, src->type, row_len);
static ggml_tensor * device_mat_row = ggml_dup_tensor(aux_ctx, host_mat_row);
ggml_set_backend(device_mat_row, GGML_BACKEND_GPU);
ggml_cuda_alloc_tensor(device_mat_row);
*ggml_cuda_get_data_pp(device_mat_row) = *ggml_cuda_get_data_pp(gpu_dst);
// read raw data and copy to device depending on gpu_idx
const enum ggml_type type = src->type;
const int ne0 = src->ne[0];
const size_t row_data_size = ne0*ggml_type_size(type)/ggml_blck_size(type);
for (int i = 0; i < gpu_rows; i++) {
int32_t host_i = ((int32_t *)gpu_bucket->data)[i];
host_mat_row -> data = (char *)(src -> data) + host_i * row_data_size;
char ** gpu_data_pp = reinterpret_cast<char **>(ggml_cuda_get_data_pp(device_mat_row));
// printf("gpu_data_p: %p\n", *gpu_data_pp);
ggml_cuda_cpy_1d(device_mat_row, host_mat_row);
*gpu_data_pp = *gpu_data_pp + row_data_size;
}
ggml_set_no_alloc(aux_ctx, false);
return gpu_dst;
#else
return NULL;
#endif
}
到这里,模型tensor被创建,数据被加载,GPU Index被计算,GPU上也被分配和卸载了相应内容,模型的初始加载过程便大致结束。
支持 ☕️
如果发现内容有纰漏或错误,可以通过邮箱hangyu.yuan@qq.com联系我或直接在下方评论告诉我,谢谢。
我的GitHub主页。