FlashAttention简析

FlashAttention 由斯坦福大学和纽约州立大学布法罗分校的研究人员提出,它是一种优化 Transformer 自注意力计算的算法,通过减少 GPU 内存访问提高计算效率,加速训练并支持更长序列处理。本文为对该算法的简单介绍分析。
背景
Attention
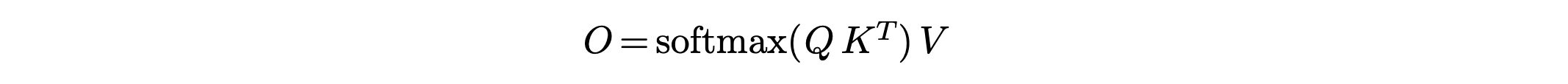
Memory Hierarchy
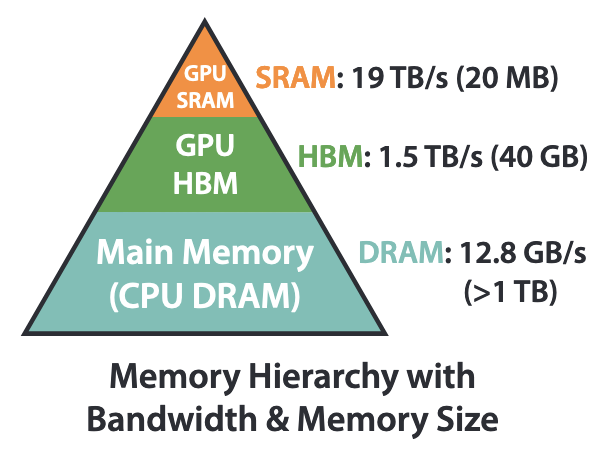
下面的HBM和DRAM大而慢,上面的SRAM快而小。
FlashAttention的垫脚石:Online Softmax
(Safe) Softmax
回顾Softmax的公式:
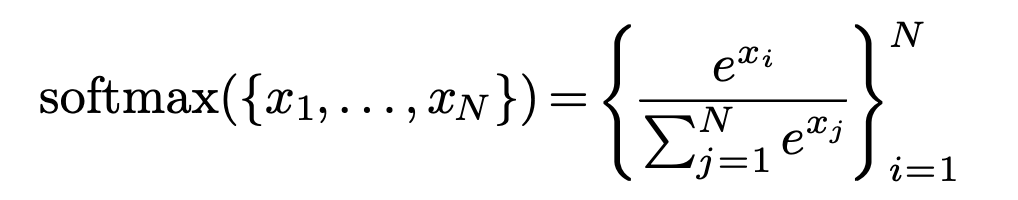
看起来简单又美好。然而,注意到是非常容易溢出的。例如,F16的最大表示值为65536,而只需要大于等于11便可使其超出F16的最大表示范围。
因此,实际应用中常常使用一种叫做“safe” softmax的trick。
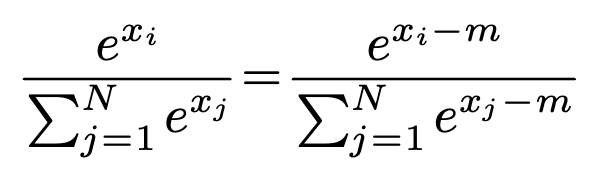
其中,,即是中的最大值。如此一来,我们便有。
于是,计算一次safe softmax,我们需要3-pass:
- 找到最大值。
- 计算。
- 计算每个softmax结果。

需要注意是在global memory中的(因为SRAM中放不下所有)。因此这里涉及到了对global memory的3轮读写,非常不I/O efficient。
从3-pass到2-pass
注意到,我们先用了一个pass来找到,再把这个用到第二个pass计算。那么,我们能不能把这两个过程合并起来呢?换句话说,是否能不用,而是用来计算?
于是,我们尝试使用来代替。既然使用的不是正确的最大值,那么我们还需要在过程中把之前所使用的错误的值去掉,替换成新的(通过乘上)。如此一来,最终会被替换成,便可使最终的。对凑项,我们便可得到如下公式。
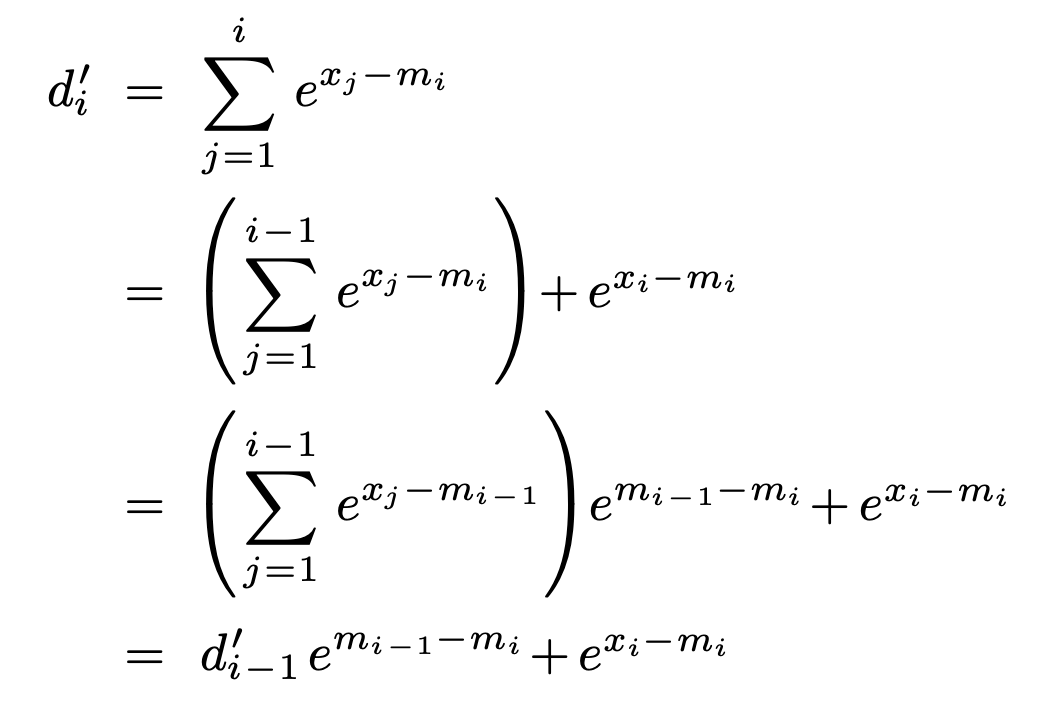
如此合并,便可得到如下的2-pass online softmax。
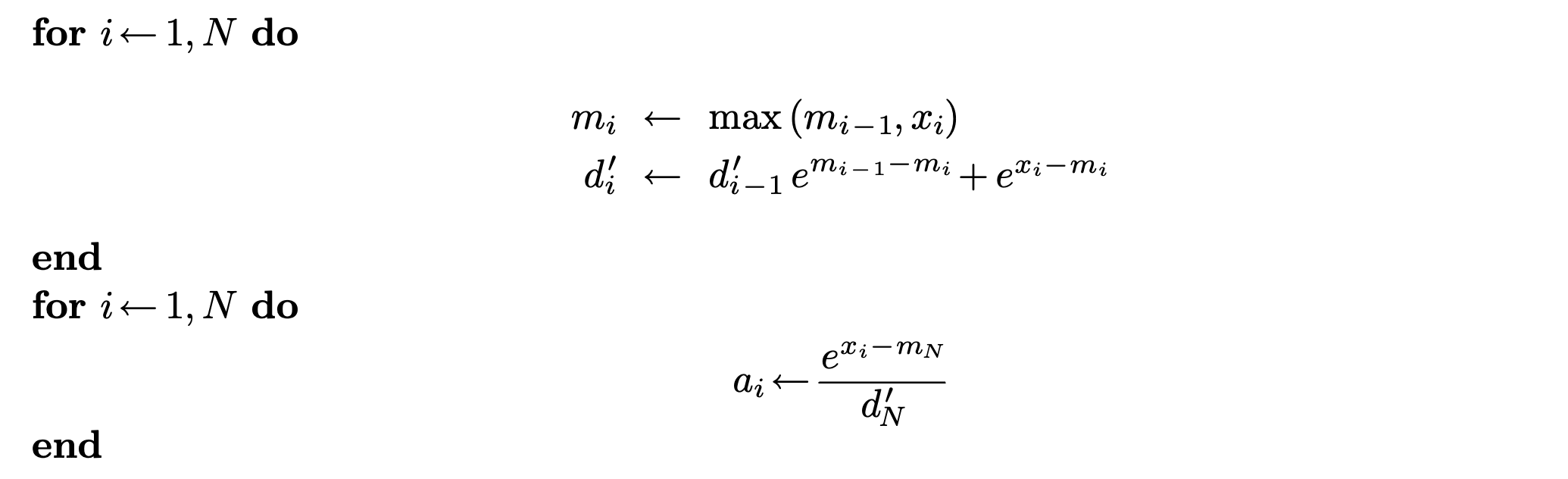
很遗憾,到了这里就不能继续合并了。因为每个的计算都严格依赖于。
FlashAttention
基本思路:尽量避免将中间结果写入DRAM。
传统Attention中矩阵的内存效率是的,这使得Attention计算过程的I/O开销不可小觑。
在矩阵乘法中,我们可以通过tiling的方式,减小每个block需处理的数据大小,从而将数据放置到较小的SRAM中以加速I/O。
要加速Attention计算过程,我们可以很容易想到可以把算子做Fusion,并通过分块的方式尽量将中间结果写到SRAM,从而减少对DRAM的读写。如果没有softmax过程,仅仅是的矩阵相乘,那么确实通过tiling就可以简单做到。
但现在的问题是,softmax是对矩阵的一整行而言的。如果做了分块,我们还如何正确计算softmax?也就是说,softmax的存在使对attention做fusion变得困难。
而FlashAttention的作者则正是利用了前文提到的online softmax所使用的思路,从而完成了这一过程。我们可以认为,online softmax使对softmax分块变为了可能。作者将这个过程一整个整合到了attention计算中,从而完成了attention计算的分块和fusion。
更重要的是,原本由于的计算依赖于导致2-pass无法继续合并。而attention计算中,我们最终只关注softmax乘上并累加的结果。这使得,我们可以在计算的过程中同时不断修正,使的计算过程不依赖而是,使得进一步的合并变得可能,如下所示。
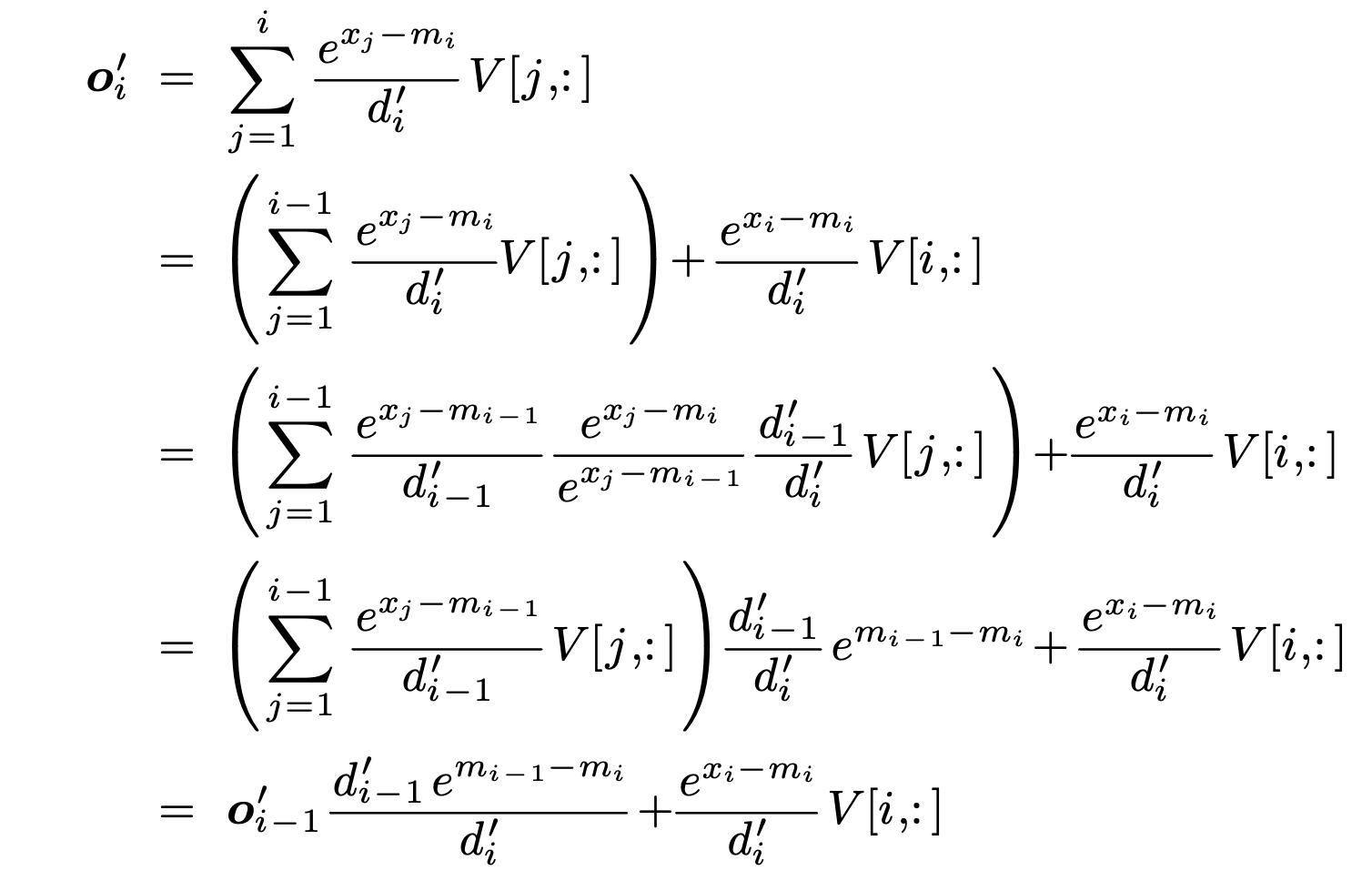
最终,分块后的计算变为了one-pass。
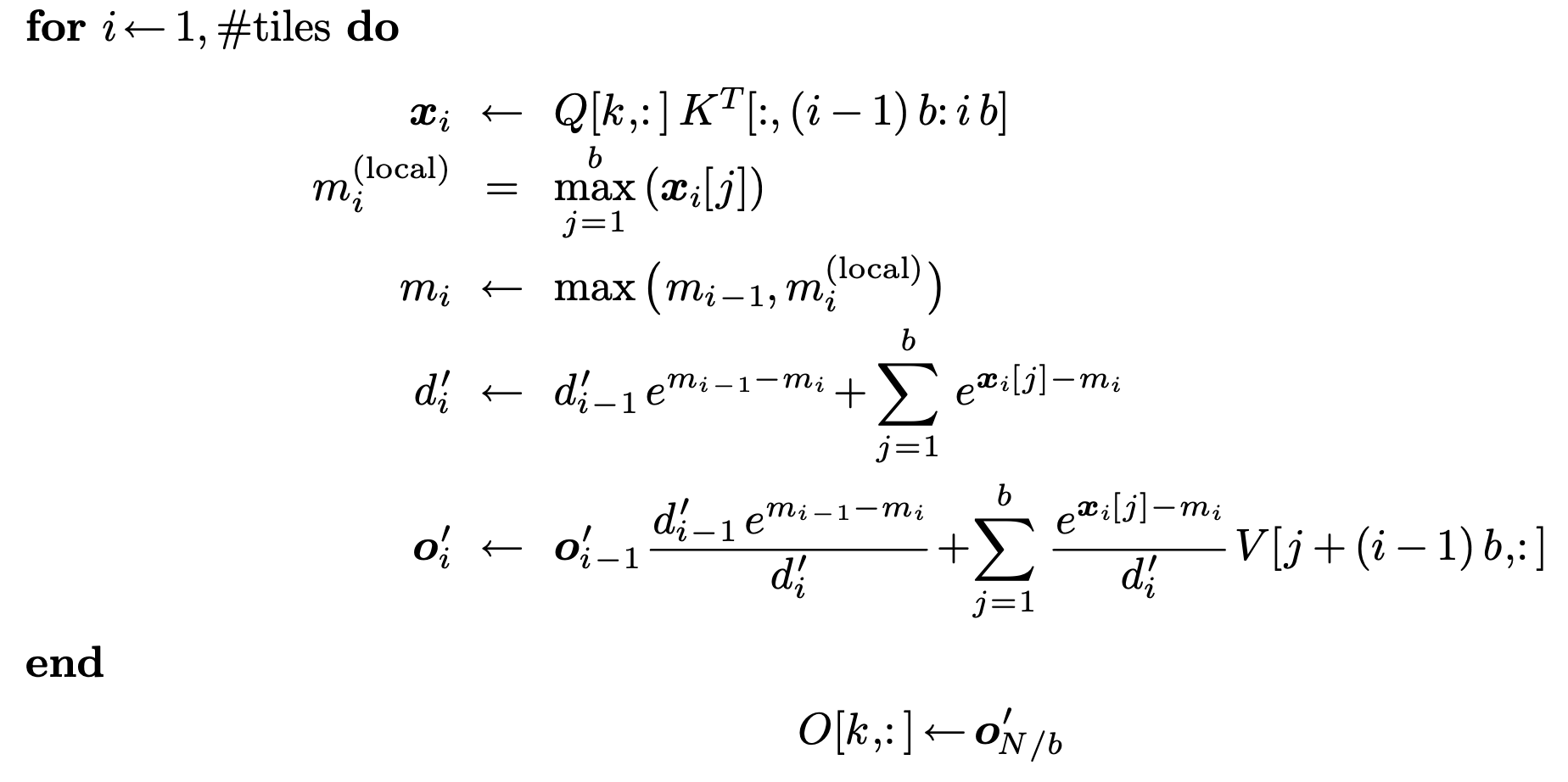
结合分块,最终有整体伪代码如下。

简单来说,外循环对、分块,内循环对分块。然后,计算,计算局部、和,更新和,乘累加到并同时用在线更新旧的。
总结
我们可以对FlashAttention的优化思路有如下概括:
目标:优化Attention的I/O效率。
--> 使用tiling和算子融合,使中间结果可以放到SRAM,减少对DRAM的I/O。
--> 问题:softmax的存在使tiling变得困难。
--> 应用online softmax方法。
至此,对FlashAttention的基本思路有了大概的了解。后续FlashAttention-v2又在此基础上有一些新的的优化,例如交换了内外分块循环的顺序等,这里就不多描述了。