ASPLOS'23 "DeepUM: Tensor Migration and Prefetching in Unified Memory" 论文解析

发表在ASPLOS'23的DeepUM是一篇关于GPU内存优化的论文。在本文中,作者提出了一个名为DeepUM的框架,利用CUDA Unified Memory(UM)来允许DNNs的GPU内存超额使用。虽然UM通过page fault机制允许内存超额使用,但page migration引入了巨大的开销。DeepUM使用一种新的correlation prefetching技术来隐藏page migration的开销。它是完全自动且对用户透明的。本文还提出了两种优化技术来最小化GPU fault handling time。作者使用来自MLPerf、PyTorch示例和Hugging Face的九个大规模DNN对DeepUM的性能进行评估,并将其性能与六种最先进的GPU内存交换方法进行比较。评估结果表明,DeepUM对于GPU内存超额使用非常有效,并且可以处理其他方法无法处理的更大模型。
Background
GPUs and CUDA Programming Model
GPGPU允许程序员在GPU上短时间处理大量的计算,这是因为GPU上有成百上千的GPU thread在同时进行计算。为了能高效地利用GPU进行计算,许多编程模型被提出,例如CUDA,oneAPI,openACC和OpenCL。
这篇论文的工作是基于CUDA的。CUDA是由NVIDIA开发的GPU并行编程模型。程序员需要定义一个CUDA kernel函数,将计算任务卸载到GPU上。然后,CUDA kernel由N个不同的CUDA线程在GPU上并行执行。每个CUDA线程都有一个唯一的thread ID,用于确定控制流和计算要访问的内存地址。CUDA thread被分组为thread block,而thread block则被分组为grid。当程序员启动一个CUDA kernel时,其可以指定grid的配置,例如一个grid上的thread block个数以及一个thread block上的thread个数。
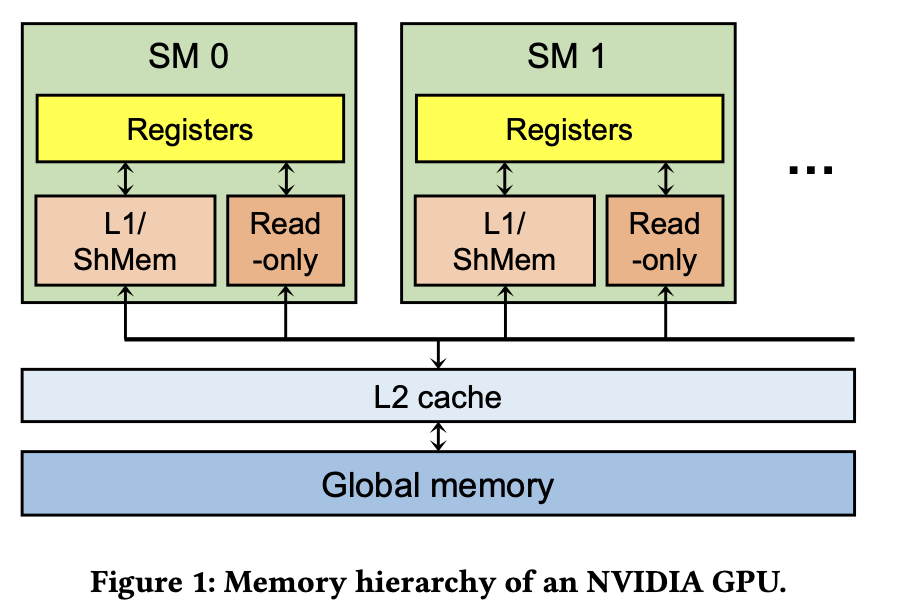
上图是NVIDIA GPU内存的层级展示。一个GPU包含了数十个streaming multiprocessors(SMs)。每个thread block被map到一个SM上(多个thread block可能被map到一个SM),每个SM内包含了数百个CUDA core,而一个thread就会被map到一个CUDA core上,所以thread block到SM,thread到CUDA core就是对应的软件到硬件的映射关系。
每个SM具有不同类型的内存单元,如寄存器、L1 cache、shared memory和constant memory(只读内存)。虽然寄存器是每个线程私有的,但其他内存单元在SM内部是共享的。在SM之外,有一个L2 cache在所有SM之间共享。Global memory是一种片外DRAM,通常是几个GB到几十个GB。通常情况下,靠近CUDA核心(SM)的存储单元具有较低的延迟和较小的容量。尽管GPU提供了几十个GB的global memory,但DNN工作负载严重缺乏global memory容量。
由于GPU线程无法直接访问main memory,除非程序员将CPU内存空间映射到GPU内存空间,程序员必须手动在GPU全局内存和CPU内存之间移动数据。此外,访问映射到GPU内存空间的CPU内存会导致性能下降,因为每次内存访问都会产生PCIe传输。为此,NVIDIA提出了统一内存(UM)的概念。
CUDA Unified Memory
UM为访问同一系统上GPU和CPU上的内存提供了单一内存空间。从Pascal架构开始,NVIDIA GPU引入了page migration engine,其使用page fault机制使GPU有了虚拟内存系统。一个page fault发生前后的snapshot如图所示。UM使得GPU内存可以超额使用,而无需程序员进行任何干预,因此极大减轻了程序员的负担。
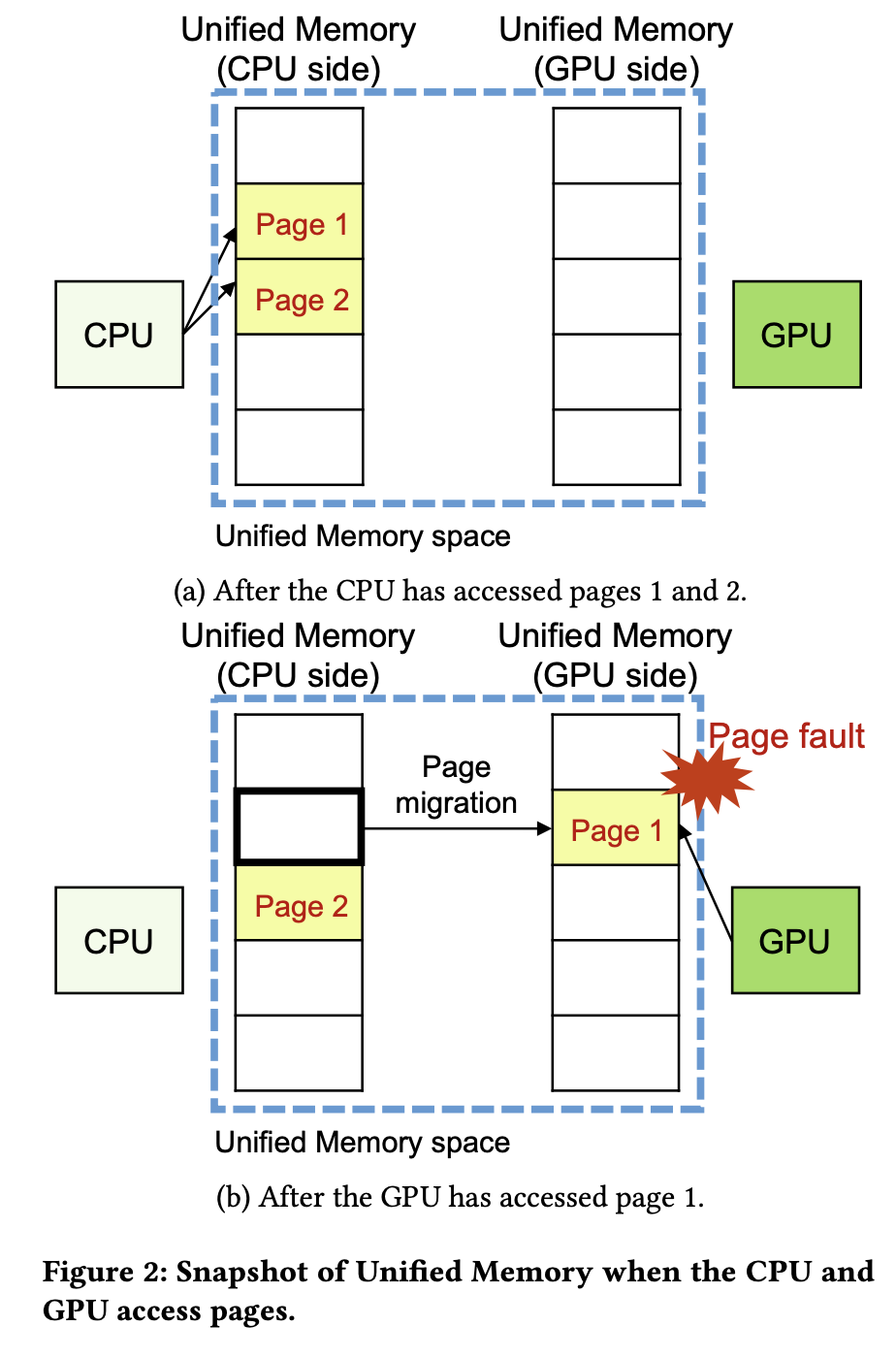
尽管UM有各种优点,GPU page fault handling的成本很高。当GPU里的一个page fault发生的时候,其对应SM的TLB会被lock住,并且在这个SM里面的所有fault被处理完之前不能做任何新的translation。此外,page faults需要在CPU和GPU之间进行昂贵的I/O操作,因此强烈建议插入CUDA prefetch API函数(例如cudaMemPrefetchAsync())或CUDA user-hint API函数(例如cudaMemAdvise()),以减少page fault的发生。
NVIDIA Page Fault Handler
Fault buffer:GPU中的一个循环队列,用于存储fault access informtion。由于GPU可以同时生成多个faults,因此fault buffer中可能包含同一page的多个fault entries。
UM block:一组最大512个连续的pages,同时也是NVIDIA driver的管理单位。
下图为NVIDIA page fault handler的一个流程图。

Motivation
随着模型参数量的越来越大,其对GPU内存的需求也越来越大,而普通用户则难以拥有如此大量且高端的GPU。幸运的是,我们可以采取将预训练的大模型再进行微调的方式获得我们想要的模型。但问题是,当前最先进的模型实在是太大了,以至于连微调都无法在一个小规模的系统上进行了,因此,许多关于GPU内存容量的研究便被开始开展,其中就包括关于memory swapping的研究。
但是之前的工作很少基于UM,主要是由于UM带来了额外的overhead。但是作者认为,使用UM能为我们带来很多好处,最重要的就是能让GPU内存被超额使用,因此还是想使用UM。但是又要想办法hide UM带来的overhead,对此作者设计了DeepUM。
Structure of DeepUM
为了隐藏上述提到UM带来的overhead,作者提出了DeepUM,其核心是对要访问的block做prefetch。

上图为DeepUM的整体结构,包含了DeepUM runtime和DeepUM driver。
-
DeepUM runtime的主要作用是为CUDA的内存分配API提供包装函数,从而将GPU内存分配请求转换为UM空间的内存分配请求。其管理了一个名为execution ID table的表,保存了kernel启动的历史记录以及由kernel的名字和参数算得的hash值。当一个新的kernel启动命令发送到DeepUM runtime时,其先为该kernel算一个hash值,然后通过该hash值去execution ID table进行查找。如果找到了,就给这个kernel相同的execution ID,否则为其分配一个新的execution ID并存储到表里面。最后,DeepUM runtime会将一个callback在kernel launch command入队(enqueue)前先入队,这个callback通过Linux ioctl将该execution ID传递给给DeepUM driver以进行后续的correlation prefetching。
-
DeepUM driver的主要作用是处理page faults以及做prefetch。DeepUM driver管理的correlation tables在DNN训练期间记录kernel执行的历史以及其访问的page,其使用这个correlation table来进行prefetch。
DeepUM driver中有四个kernel threads,分别是
- fault handling thread,负责读取fault buffer,将信息传递给其他线程。
- correlator thread,负责管理correlation table。
- prefetching thread,负责查询correlation table,并据此计算要prefetch的UM block地址。
- migration thread,负载在GPU和CPU之间做UM block的迁移。
图中还有两个queue,分别是fault queue和prefetch queue。fault queue相比prefetch queue拥有更高的优先级(被migration thread执行),以让GPU可以尽快的对faulted accesses进行reply。
Correlation Prefetching for GPU Pages
Pair-Based Correlation Prefetching
传统的correlation prefetch有两种方法,分别是stride-based和pair-based。DeepUM是基于pair-based的。pair-based correlation prefetching如图所示。NumLevels表示不同的level,比如c是a的后一个的后一个,所以放在第二个level;NumSuccs则是MRU从左到右排序的。

Correlation Prefetching in DeepUM
两种Correlation Table
和原始的correlation prefetching不一样,DeepUM使用了两种类型的correlation table:execution ID和UM block,两种类型的NumLevels都为1。
- execution ID correlation table (the execution table in short):记录exexcution ID(也就是对应CUDA kernel)的执行历史。Execution table只存在一个。一个execution table的示例如图所示。

由上图可见,每个entry由多组correlated IDs组成,每一组包含了四个execution ID。其中前三个表示在当前kernel之前执行过的kernel,第四个表示预测在当前kernel的下一个要执行的kernel。注意这里下一个kernel预测错误带来的开销是很昂贵的。 - UM block correlation table (a block table in short):记录UM block的访问历史。相比全局只存在一个的execution table,block table是对于每个execution ID都有一个的。一个block table的示例如图所示。
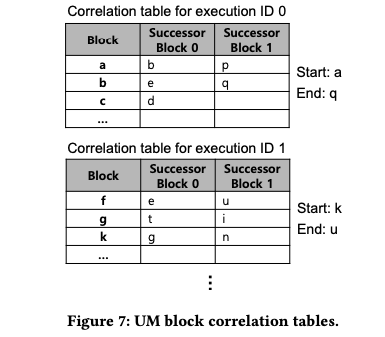
我们提到block table是对于每个execution ID都有一个的,如图所示,其记录的也是相对应的CUDA kernel内的UM block访问历史。可以观察到,虽然这个table和原始的correlation table结构相似,但是多出了一个start UM block和一个end UM block的指针。- start UM block指向这个kernel执行中第一个发生fault的UM block。
- end UM block指向这个kernel执行中最后一个要prefetch的UM block。end UM block记录的实际就是当前kernel执行结束前最后一个发生fault的UM block。
Prefetching Mechanisms and Chaining
当page fault发生,DeepUM driver就去查找当前执行的kernel的对应的UM block correlation table,然后去对faulted UM block这条后面记录的correlated UM block内的所有pages做prefetch。
那么start UM block和end UM block发挥了什么作用呢?当prefetching thread遇到了end block时,就结束对当前kernel的prefetch,然后通过查阅execution ID table预测下一个要执行的kernel,接着对下一个kernel的end block进行prefetch。也就是说,start UM block和end UM block是用来配合之前提到的execution ID correlation table做chaining的。
那么chaining什么时候结束?关于prefetch和chaining,文中提到了三个时间节点:
- 当出现一个新的page fault interrupt signal,或者prefetching thread错误预测了下一个要执行的kernel,chaining结束。
- 当prefetching thread把后续N个kernel的prefetch commands都已经enqueue了,chaining暂停。
- 当前正在执行的kernel执行结束后,prefetching thread继续。
Optimizations for GPU Page Fault Handing
文中提到了两种针对page fault handing的优化,分别为page pre-eviction和Invalidating UM Blocks of Inactive PyTorch Blocks。
Page Pre-eviction
当要migrating faulted pages时,GPU内存分配失败,就会触发eviction。正如图中对X,Y的eviction,page eviction的发生会增大fault handling的时间。
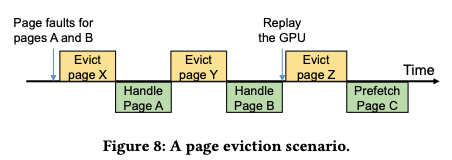
因此,作者想到在GPU内存空间不足时去做pre-eviction。具体来说,当page满足下列两个条件时,就会被evict。
- 最久未迁移(Least recently migrated)
- 预计不会被当前正在执行的kernel以及接下来的N个被预测将执行的kernel访问
Invalidating UM Blocks of Inactive PyTorch Blocks
Pytorch Memory Pool与PT Block
PyTorch通过管理memory pools的方式来最小化内存的分配和释放的时间,同时减小内存碎片。PyTorch中的memory pool有两种:large和small。PyTorch中的内存对象也叫做block,为了和UM block作区分,我们称其为PT block。large pool包含了超过1MB的PT blocks,而small pool包含了小于或等于1MB的PT blocks。PyTorch的内存分配器会返回最小可用的PT block,并且如果PT block的size还是太大,则会将其做split。
这里的关键在于,当PT block被DNN模型使用结束,返回到内存分配器时,内存分配器只会将其mark成inactive(当然还要放回合适的memory pool)而不是直接free掉(对于设备来说),除非pool中没有可用的内存空间了,才会把inactive的PT block释放掉来生成新的内存空间。
Invalidating UM Blocks
上面的机制被放在与UM一起使用时就会出现问题,即inactive的PT blocks也会被evicted到CPU内存上,造成不必要的数据传输开销。并且,这还占用了CPU的内存空间。更严重的场景是,当这些inactive的PT blocks又被mark成active,那还要再把这些PT blocks从CPU迁移到GPU,造成更多不必要的数据传输。
因此,作者的思路很简单,也就是在PyTorch的内存分配器中加入少量代码,来告诉DeepUM driver何时一个PT block被标记成了inactive。如果一个将要evict的page属于一个inactive PT block,那么DeepUM driver就直接简单将其对应的UM block invalidate就好。
Evaluation
限于篇幅原因,对这部分内容只给出一些大概的结论总结,如果对具体的实验数据或者实验细节感兴趣可以去阅读论文原文。
作者首先将将DeepUM与Naive UM和IBM LMS做了一个对比。结果显示:
- 和其他内存预取策略一样,DeepUM的性能依赖于应用的memory access patterns以及内存迁移时间和计算时间相比的比例。例如在DLRM这样的模型上,内存的访问模式不规则(因为高度依赖输入数据),导致LMS与DeepUM在上面都运行得不好。
- DeepUM相比LMS和LMS-mod(LMS的修改版本,速度慢一些但是能比LMS运行更大的batch size)能运行更大的batch size。这是通过虚拟内存的支持做到的。
- 平均来看,DeepUM有着最好的性能,相比UM有3.06✕的加速比,相比LMS有1.11✕的加速比。
- 虽然LMS有着最好的能耗,但是LMS与DeepUM之间的差距很小
作者还进了其他的一些测试,例如:
- 作者评估了存储correlation table所用的大小。这个大小随着模型与batch size而变化。注意correlation table是存储在CPU内存的。
- 作者评估了page faults发生的次数,结果显示DeepUM的prefetch相当精准,并且能大量减少page fault发生的次数。
- 作者评估了prefetching和optimizations所带来的效果,结果显示prefetching,prefetching+preeviction和prefetching+preeviction+invalidate分别平均减小了45.6%,63.7%和66.7%的运行时间。
- 作者评估了预取的不同程度(即N的大小)带来的的影响,结果显示,当N=32时,加速比最高,同时能耗最低。
- 作者评估了UM Block Correlation Table的不同参数配置带来的影响,结果显示,当Assoc为2,NumSuccs为4,NumRows为2048时,能带来相对最好的效果。
作者还将DeepUM与5个TensorFlow-Based的研究的实验数据进行了比较,结果显示DeepUM拥有与Sentinel相当的性能,比剩余其他的几个都快。但是Sentinel是需要手动优化的,而DeepUM是对用户透明的。并且,DeepUM相比之前的方法能允许更大的batch size。作者将这种性能的差别归于DeepUM对数据移动的更小的粒度。
Related Work
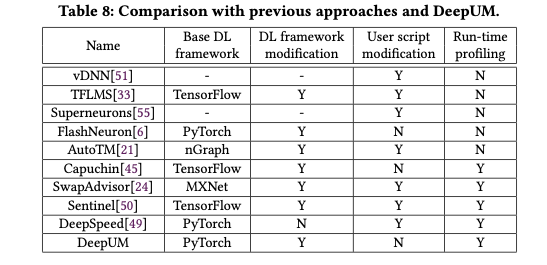
作者回顾了以前的研究,最后将多个工作放在一起进行了一个比较,结果如图所示。
Conclusions
随着模型参数量的越来越大,其对GPU内存的需求也越来越大,而普通用户则难以拥有如此大量且高端的GPU。幸运的是,我们可以采取将预训练的大模型再进行微调的方式获得我们想要的模型。但问题是,当前最先进的模型实在是太大了,以至于连微调都无法在一个小规模的系统上进行了,因此,许多关于GPU内存容量的研究便被开始开展,本文便是一篇关于memory swapping的文章。
之前的工作很少基于UM,主要是由于UM带来了额外的overhead。但是作者认为,使用UM能为我们带来很多好处,最重要的就是能让GPU内存被超额使用。对此作者设计了DeepUM。
为了隐藏UM带来的overhead,DeepUM通过prefetch策略,减少page fault的发生,同时提出了pre-eviction和invalidate block两种优化来减小处理page fault时的开销。
测试显示,DeepUM能达到与需要手动优化的Sentinel相当的性能,并比其他几个baseline的性能都要好。同时,DeepUM也能处理其他几个方法处理不了的更大的模型。